
En mi anterior post, Descubriendo la regresión logística, dejaba indicado que, para estimar los coeficientes del modelo de regresión logística, se aplica el método de máxima verosimilitud (maximum likelihood, en inglés). En realidad este método se puede utilizar para calcular los parámetros de cualquier otro modelo.
¿En qué consiste este método?
Bueno, para una muestra aleatoria de sucesos independientes, idénticamente distribuidos (x1,…,xn), cuya distribución depende de un parámetro θ, la función de verosimilitud se define así:
![\[ \mathcal{L}(\theta ) = f(x_{1};\theta)\cdots f(x_{n};\theta) = \prod_{i=1}^{n}f(x_{i};\theta) \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-6c240660ec94a70152abcc35bf61b6d9_l3.png "Rendered by QuickLaTeX.com")
Por conveniencia, para hacer más sencillos los cálculos, se suele utilizar el logaritmo de la función de verosimilitud, también llamada (log)verosimilitud, que tiene esta pinta:
![\[ \ell(\theta) = \ln\mathcal{L}(\theta) = \ln\prod_{i=1}^{n}f(x_{i};\theta) = \sum_{i=1}^{n}\ln f(x_{i};\theta) \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-8611ed4d5d21dd92f042f6c672ee915d_l3.png "Rendered by QuickLaTeX.com")
Con el método de máxima verosimilitud, obtendremos el valor del parámetro θ que maximice la función de verosimilitud anterior. Al parámetro θ se le llama estimación de máxima verosimilitud, (EMV).
Como ya sabemos, en la regresión logística la variable respuesta, yi, sigue una distribución de Bernoulli tal que:
![\[ y_{i} = \begin{cases} 0 & P_{i}(0) = 1-p_{i}\\ 1 & P_{i}(1) = p_{i} \end{cases} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-ea7945899042d5aeaf2ec42e17a7b28e_l3.png "Rendered by QuickLaTeX.com")
y su función de probabilidad tiene esta pinta:
![\[ f(y_{i}) = p_{i}^{y_{i}} \cdot (1-p)_{i}^{1-y_{i}} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-e02f4c4e564c6ff6557412d4ea3692f4_l3.png "Rendered by QuickLaTeX.com")
Si recordamos, dos de las expresiones que obtuvimos en Descubriendo la regresión logística eran:
(1) 
(2) 
donde pi es la probabilidad de que ocurra el evento, xip son los factores y bi los parámetros asociados a cada factor, que, en principio, están relacionados con la probabilidad de que el suceso ocurra. Por ejemplo, para dos únicos parámetros tales que b0 = a y xi0 = 1 y b1 = b tendríamos la expresión para un regresión lineal simple:
![\[\ln\begin{pmatrix}\frac{p_{i}}{1-p_{i}}\end{pmatrix}=a + b\cdot x_{i}\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-dfa0fcdda3b41aaa85c228f9262debec_l3.png "Rendered by QuickLaTeX.com")
Así pues, B son los parámetros que necesitamos estimar.
Entonces, partiendo de la definición para la función de verosimilitud hacemos lo siguiente:
![\[ \mathcal{L}(b) = \prod_{i=1}^{n}f(y_{i})=\prod_{i=1}^{n}p_{i}^{y_{i}} \cdot (1-p)_{i}^{1-y_{i}}\Rightarrow \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-e4edb9dac529d1607e54f0fbe0e65006_l3.png "Rendered by QuickLaTeX.com")
![\[ \rightarrow \enspace Aplicamos \enspace logaritmos \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-d459f70cf7766e9ea707d5c47c437317_l3.png "Rendered by QuickLaTeX.com")
![\[ \ln\mathcal{L}(b) = \ell(b) = \ln \prod_{i=1}^{n}p_{i}^{y_{i}} \cdot (1-p)_{i}^{1-y_{i}}= \sum_{i=1}^{n} y_{i}\ln p_{i} + (1-y_{i})\ln(1-p_{i})\Rightarrow \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-8bdcee62ff745f45f81c8f4d065f1771_l3.png "Rendered by QuickLaTeX.com")
![\[\Rightarrow \ell(b) =\sum_{i=1}^{n} y_{i}\ln p_{i}+\ln(1-p_{i})-y_{i}\ln(1-p_{i}) = \sum_{i=1}^{n}y_{i}(\ln p_{i}-\ln(1-p_{i}) ) + \ln(1-p_{i})\Rightarrow\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-511cb10503f32ea1fc68f1de1c5ee1e3_l3.png "Rendered by QuickLaTeX.com")
![\[ \begin{array}{lcl} \rightarrow \enspace Aplicamos \enspace que \enspace \ln p_{i}-\ln(1-p_{i}) = \ln\begin{pmatrix}\frac{p_{i}}{1-p_{i}}\end{pmatrix} \\ \rightarrow \enspace Aplicamos \enspace la \enspace ecuaci\acute{o}n \enspace (1) \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-ff4ef00eeca51b95108a62c8fe421826_l3.png "Rendered by QuickLaTeX.com")
![\[\Rightarrow \ell(b) = \sum_{i=1}^{n}y_{i}\ln\begin{pmatrix}\frac{p_{i}}{1-p_{i}}\end{pmatrix} + \ln(1-p_{i}) = \sum_{i=1}^{n}y_{i}(B\cdot x_{i}) + \ln(1-p_{i}) \Rightarrow\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-fdd82633f46c95693fbc4da1917d16aa_l3.png "Rendered by QuickLaTeX.com")
![\[ \begin{array}{lcl} \rightarrow \enspace Aplicamos \enspace lo \enspace siguiente, utilizando \enspace la \enspace ecuaci\acute{o}n \enspace (2): \\ 1-p_{i}=1-\frac{1}{1 + e^{-(B\cdot x_{i})}}=\frac{1-e^{-(B\cdot x_{i})}+1}{1 + e^{-(B\cdot x_{i}}}=\frac{e^{-(B\cdot x_{i})}}{1+e^{-(B\cdot x_{i})}}= \frac{1}{e^{(B\cdot x_{i})}+1} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-ea7b3ad734fef907157e4e16239c281b_l3.png "Rendered by QuickLaTeX.com")
![\[\Rightarrow \ell(b) = \sum_{i=1}^{n}y_{i}\cdot B\cdot x_{i}+ \ln\begin{pmatrix}\frac{1}{e^{(B\cdot x_{i})}+1}\end{pmatrix})=\sum_{i=1}^{n}y_{i}\cdot B\cdot x_{i}+\ln1 - \ln(e^{(B\cdot x_{i})}+1) \Rightarrow\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-e1bba9b640cb32514d7119be2494c3df_l3.png "Rendered by QuickLaTeX.com")
![\[ \Rightarrow \boxed{\ell(b) = \sum_{i=1}^{n}y_{i}\cdot B\cdot x_{i}- \ln(e^{(B\cdot x_{i})}+1)} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-d11a65a36ad0379cb0f03616ce9645e8_l3.png "Rendered by QuickLaTeX.com")
Una vez que tenemos nuestra función (log)verosimilitud, tenemos que maximizarla.
Para ello lo primero que tenemos que hacer es calcular las derivadas parciales de la función respecto a los parámetros B:
![\[\frac{\partial \ell(b)}{\partial b}=\frac{\partial \sum_{i=1}^{n}y_{i}\cdot B\cdot x_{i} - \ln(e^{(B\cdot x_{i})}+1)}{\partial b}=\sum_{i=1}^{n} y_{i}\cdot x_{i} - \frac{e^{(B\cdot x_{i})}}{e^{(B\cdot x_{i})}+1}= \sum_{i=1}^{n} y_{i}\cdot x_{i} - \frac{1}{e^{-(B\cdot x_{i})}+1} \Rightarrow\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-7d30ed8adfc62ba9c70045cf9f14b6f7_l3.png "Rendered by QuickLaTeX.com")
![\[ \begin{array}{lcl} \rightarrow Aplicamos: \\ p_{i} = \frac{1}{1 + e^{-(B\cdot x_{i})}} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-03644505700b65c629bab49719ce522c_l3.png "Rendered by QuickLaTeX.com")
![\[\Rightarrow \frac{\partial \ell(b)}{\partial b} = \sum_{i=1}^{n} y_{i}\cdot x_{i} - p_{i}\cdot x_{i} = \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-c2cb40e325d725ca5af4ae28f691b320_l3.png "Rendered by QuickLaTeX.com")
La expresión para la primera derivada podemos escribirla en notación matricial así:
![\[ \boxed{\frac{\partial \ell(b)}{\partial b} = X(y - p)} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-666b21aed3fd8f6042e71317a198aeae_l3.png "Rendered by QuickLaTeX.com")
Ahora vamos a calcular la segunda derivada de la función:
![\[\frac{\partial^2 \ell(b)}{\partial b^2} = -x_{i}\cdot \frac{\partial p_{i}}{\partial b} \Rightarrow \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-4704dde5e2b59ad9866669021c02517e_l3.png "Rendered by QuickLaTeX.com")
![\[ \begin{array}{lcl} \rightarrow Calculamos \enspace \frac{\partial p_{i}}{\partial b}\\ \frac{\partial p_{i}}{\partial b}=\frac{\partial }{\partial b}\left ( \frac{1}{1 + e^{-(B\cdot x_{i})}} \right )= \frac{-e^{-(B\cdot x_{i})}\cdot x_{i}}{\left ( 1 + e^{-(B\cdot x_{i})} \right )^{2}} = -\frac{1}{1 + e^{-(B\cdot x_{i})}}\cdot\frac{e^{-(B\cdot x_{i})}}{1 + e^{-(B\cdot x_{i})}}\cdot x_{i} = -p_{i}\cdot (1-p_{i})\cdot x_{i} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-85239feec5a112e2416756e764e8c20d_l3.png "Rendered by QuickLaTeX.com")
![\[\Rightarrow \frac{\partial^2 \ell(b)}{\partial b^2} = \sum_{i=1}^{n}x_{i}\cdot p_{i}\cdot (1-p_{i})\cdot x_{i}\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-7db58a45afcd111bf9acc053fb8af2c7_l3.png "Rendered by QuickLaTeX.com")
En notación matricial sería:
![\[ \boxed{\frac{\partial^2 \ell(b)}{\partial b^2} = X\cdot W \cdot X^{T}} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-f5a107175f9d26d5ffbdd8e4e06e52c8_l3.png "Rendered by QuickLaTeX.com")
donde W es la matriz diagonal:
![\[ W = \begin{pmatrix} \cdots & & \\ & p_{i}(1-p_{i}) & \\ & & \cdots \end{pmatrix} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-500811401398cf7ea58cb59b2c6c4b66_l3.png "Rendered by QuickLaTeX.com")
Para calcular los extremos (máximos y mínimos) de una función, hay que igualar a cero la primera derivada de dicha función, y despejar los coeficientes. Pero, dependiendo de la función, ésto no siempre es sencillo. Para ayudarnos en esa tarea, existe otro método, el método de Newton-Raphson. Con éste método podemos aproximar los valores de las raíces de cualquier función. Es un método iterativo que utiliza esta ecuación para actualizar los parámetros en cada iteración:
![\[b_{n+1}= b_{n} - \frac{f(b_{n})}{{f}'(b_{n})} \Rightarrow\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-46ef449982facf0bb347ecd6836e1910_l3.png "Rendered by QuickLaTeX.com")
![\[ \Rightarrow\Delta b=\frac{f(b_{n})}{{f}'(b_{n})}\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-f8137ba40dc732b49ed9719b1289f356_l3.png "Rendered by QuickLaTeX.com")
En nuestro caso, teniendo en cuenta que f(bn) sería igual a la expresión de nuestra primera derivada y f'(bn) sería igual a la expresión de la segunda derivada, la iteración de Newton-Raphson se escribiría así:
![\[ \boxed{\Delta b=(XWX^{T})^{-1}X(y-p)} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-816614a1af7382ad586b2f2bd259d955_l3.png "Rendered by QuickLaTeX.com")
El algoritmo de estimación de los coeficientes B es el siguiente:
- Damos un valor al coeficiente b = 0.
- Se estima el vector p de probabilidades para cada evento (que en esta primera iteración serán pi =0.5) y la matriz W.
- Se calcula el vector z.
- Se actualiza b.
Los pasos 2 al 4 se repiten hasta lograr la convergencia. Aunque ésta no se garantiza siempre, lo normal es alcanzarla.
Bueno, pues vamos a dejar la teoría y vamos a intentar poner todo lo que hemos visto hasta ahora en práctica, desarrollando un programita en Python para hacer todos estos cálculos, y obtener los coeficientes de una regresión logística.
Empezamos importando los módulos que vamos a necesitar:
#Import the modules we are going to need import pandas as pd import numpy as np from sklearn import linear_model, metrics from sklearn.model_selection import train_test_split import statsmodels.api as sm import seaborn as sns import matplotlib.pyplot as plt
Lo siguinte que haremos será generar unos datos, que si no ,no hacemos nada :-). Lo haremos con la función genDataset que cree en el post Atrévete a crear tu propio dataset. Vamos a crear un dataset con 4 características y 50000 registros, con valores entre 0 y 10, por ejemplo.
data = genDataset(n_features = 4, n_samples = 50000, low = 0, high = 10,
weights = [0.125, 0.375, 0.125, 0.375],
threshold = 6)
data.columns = ['f1', 'f2', 'f3', 'f4', 'y']
Echamos un vistazo a los datos:
data.describe().transpose()
count mean std min 25% 50% 75% max f1 50000.0 4.52080 2.866079 0.0 2.0 5.0 7.0 9.0 f2 50000.0 4.52328 2.878233 0.0 2.0 5.0 7.0 9.0 f3 50000.0 4.51066 2.875999 0.0 2.0 5.0 7.0 9.0 f4 50000.0 4.51058 2.864523 0.0 2.0 5.0 7.0 9.0 y 50000.0 0.20136 0.401020 0.0 0.0 0.0 0.0 1.0
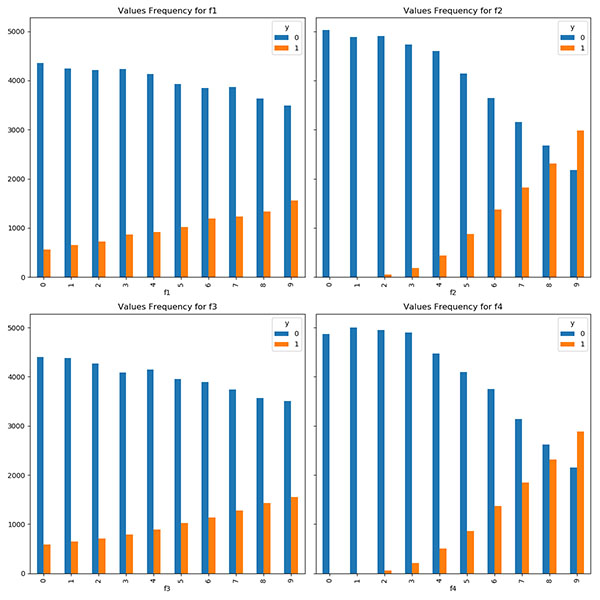
fig, axs = plt.subplots(2, 2, figsize=(12, 12), sharey=True) pd.crosstab(data['f1'],data['y']).plot( kind='bar', ax = axs[0][0], title = 'Values Frequency for f1') pd.crosstab(data['f2'],data['y']).plot(kind='bar', ax = axs[0][1], title = 'Values Frequency for f2') pd.crosstab(data['f3'],data['y']).plot(kind='bar', ax = axs[1][0], title = 'Values Frequency for f3') pd.crosstab(data['f4'],data['y']).plot(kind='bar', ax = axs[1][1], title = 'Values Frequency for f4') plt.show()
sns.countplot(x='y', data=data, palette='hls') plt.show()
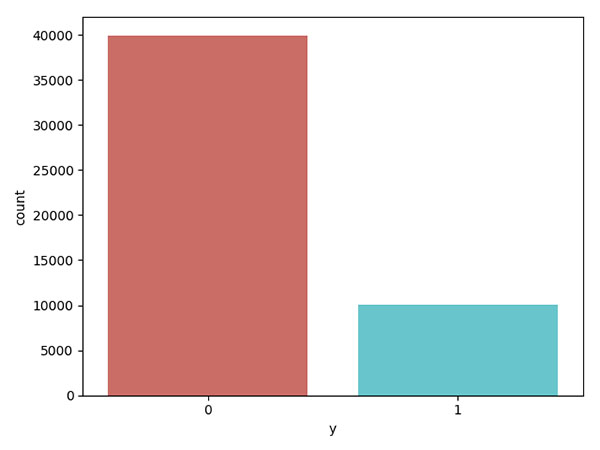
count_zeros = len(data[data['y']==0])
count_ones = len(data[data['y']==1])
percent_zeros = count_zeros/(count_zeros+count_ones)
percent_ones = count_ones/(count_zeros+count_ones)
print(f'zeros percentage: {percent_zeros*100}')
print(f'ones percentage: {percent_ones*100}')
zeros percentage: 79.864 ones percentage: 20.136000000000003
Bueno, ahora que ya tenemos unos datos preparados, vamos a crear el modelo.
Definiremos una clase, a la que llamaremos LogReg_mv:
class LogReg_mv():
def __init__(self, increment, X, Y):
"""
:param increment: is the limit increase for the algorithm to converge
:param X: matrix of the predictor variables
:param Y: matrix of the response variables
"""
self.increment = increment
self.X = X
self.Y = Y
# We give an initial value of 0 to the coefficients. Matriz: one column, n rows.
self.B = np.zeros(X.shape[1]).reshape(X.shape[1], 1)
Añadiremos los siguientes métodos:
El método w_matrix para calcular la matriz W:
def w_matrix(self, pi):
"""
function for calculating the W matrix
:param pi: matrix of probabilities associated with each event
:return: matrix W
"""
w = np.identity(len(pi))
for index, p in enumerate(pi):
w[index][index] = float(p * (1 - p))
return w
El método prob_matrix para calcular la probabilidad asociada a cada suceso:
def prob_matrix(self, B):
"""
function for the calculation of the sigmoid function
:param B: matrix of the coefficients
:return: matrix of probabilities associated with each event
"""
import numpy as np
exponents = []
pi = []
for i, row in enumerate(self.X):
exponent = sum([x * B[index] for index, x in enumerate(row)])
exponents.append(exponent)
p = 1 / (1 + np.exp(-exponent))
pi.append(p)
return pi
El método fit para el cálculo de los coeficientes:
def fit(self):
"""
function that calculates the coefficients of the logistic regression
"""
import numpy as np
from numpy import linalg
self.num_iter = 0
self.increments_list = []
while True:
p = self.prob_matrix(self.B)
w = self.w_matrix(p)
first_order_der = np.dot(np.transpose(self.X), np.subtract(self.Y, np.transpose(p)).transpose())
second_order_der = np.transpose(self.X).dot(w).dot(self.X)
# delta: incremento
delta = np.transpose(np.dot(np.transpose(first_order_der), linalg.inv(second_order_der)))
self.B = self.B + delta
self.num_iter = self.num_iter + 1
increment = np.sum(np.power(delta, 2))
self.increments_list.append(increment)
if increment <= self.increment:
break
equation = f'Y = '
for i, b in enumerate(self.B):
if i == 0:
equation_2 = f'{round(b[0],4)} '
else:
if b[0] < 0:
equation_2 = equation_2 + f'{round(b[0],4)}⋅X{i} '
else:
equation_2 = equation_2 + f'+ {round(b[0],4)}⋅X{i} '
print('Logistic regresion model fitted')
print(f'Completed in {self.num_iter} iterations')
print('Increments')
print(self.increments_list)
print('Coefficients:')
print(self.B)
print('Equation:')
print(equation + equation_2)
# return self.B
Y por último, el método predict, para predecir los valores de la variable respuesta:
def predict(self, X):
"""
function that calculates the values for the response variable
:param X: test dataset with the predictors variables
:return p_list: list with the values for the response variable.
"""
p_list = []
for ele in np.array(X):
y = float(np.dot(ele, self.B))
p = 1 / (1 + np.exp(-y))
if p >= 0.5:
p_list.append(1)
else:
p_list.append(0)
return p_list
Con lo que nuestra clase tendría esta pinta:
class LogReg_mv():
def __init__(self, increment, X, Y):
"""
:param increment: is the limit increase for the algorithm to converge
:param X: matrix of the predictor variables
:param Y: matrix of the response variables
"""
self.increment = increment
self.X = X
self.Y = Y
# We give an initial value of 0 to the coefficients. Matriz: one column, n rows.
self.B = np.zeros(X.shape[1]).reshape(X.shape[1], 1)
def w_matrix(self, pi):
"""
function for calculating the W matrix
:param pi: matrix of probabilities associated with each event
:return: matrix W
"""
w = np.identity(len(pi))
for index, p in enumerate(pi):
w[index][index] = float(p * (1 - p))
return w
def prob_matrix(self, B):
"""
function for the calculation of the sigmoid function
:param B: matrix of the coefficients
:return: matrix of probabilities associated with each event
"""
import numpy as np
exponents = []
pi = []
for i, row in enumerate(self.X):
exponent = sum([x * B[index] for index, x in enumerate(row)])
exponents.append(exponent)
p = 1 / (1 + np.exp(-exponent))
pi.append(p)
return pi
def fit(self):
"""
function that calculates the coefficients of the logistic regression
"""
import numpy as np
from numpy import linalg
self.num_iter = 0
self.increments_list = []
while True:
p = self.prob_matrix(self.B)
w = self.w_matrix(p)
first_order_der = np.dot(np.transpose(self.X), np.subtract(self.Y, np.transpose(p)).transpose())
second_order_der = np.transpose(self.X).dot(w).dot(self.X)
# delta: incremento
delta = np.transpose(np.dot(np.transpose(first_order_der), linalg.inv(second_order_der)))
self.B = self.B + delta
self.num_iter = self.num_iter + 1
increment = np.sum(np.power(delta, 2))
self.increments_list.append(increment)
if increment <= self.increment:
break
equation = f'Y = '
for i, b in enumerate(self.B):
if i == 0:
equation_2 = f'{round(b[0],4)} '
else:
if b[0] < 0:
equation_2 = equation_2 + f'{round(b[0],4)}⋅X{i} '
else:
equation_2 = equation_2 + f'+ {round(b[0],4)}⋅X{i} '
print('Logistic regresion model fitted')
print(f'Completed in {self.num_iter} iterations')
print('Increments')
print(self.increments_list)
print('Coefficients:')
print(self.B)
print('Equation:')
print(equation + equation_2)
# return self.B
def predict(self, X):
"""
function that calculates the values for the response variable
:param X: test dataset with the predictors variables
:return p_list: list with the values for the response variable.
"""
p_list = []
for ele in np.array(X):
y = float(np.dot(ele, self.B))
p = 1 / (1 + np.exp(-y))
if p >= 0.5:
p_list.append(1)
else:
p_list.append(0)
return p_list
El siguiente paso será utilizar la función train_test_split para dividir el dataset en dos datasets, uno de entrenamiento y otro de prueba:
X = data.iloc[:,0:4]
y = data.iloc[:,4]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
Genial. Ya podemos entrenar a nuestro modelo:
reglog_model = LogReg_mv(increment = 0.000001, X = np.array(X_train), Y = np.array(y_train)) reglog_model.fit()
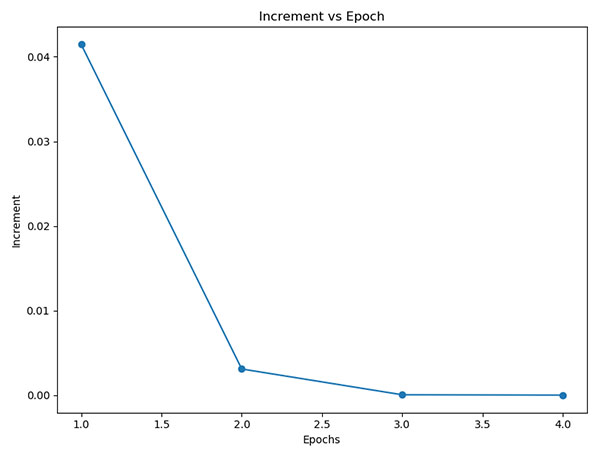
Logistic regresion model fitted Completed in 4 iterations Increments [0.04145047107036892, 0.003084416551459915, 3.50808031008695e-05, 3.5445540542615975e-09] Coefficients: [[-0.17943204] [ 0.06895 ] [-0.16914413] [ 0.06658092]] Equation: Y = -0.1794 + 0.069⋅X1 -0.1691⋅X2 + 0.0666⋅X3
Nos dice que ha necesitado 4 iteraciones para conseguir esos coeficientes.
Podemos sacar una gráfica con el incremento de cada iteración:
plt.figure(figsize=(15, 6))
plt.subplot(121)
plt.plot(range(1, len(reglog_model.increments_list) + 1),reglog_model.increments_list, marker='o')
plt.title('Increment vs Epoch')
plt.xlabel('Epochs')
plt.ylabel('Increment')
plt.tight_layout()
plt.show()
Le pedimos al modelo la variable respuesta para el dataset X_test
y_pred = reglog_model.predict(X_test)
Evaluamos el modelo. Podemos utilizar la matriz de confusión:
print ('CONFUSION MATRIX')
predictions = y_pred
cm = metrics.confusion_matrix(y_test, y_pred)
acc = metrics.accuracy_score(y_test, y_pred)
fig = plt.figure(figsize=(10,6))
cm_char = fig.add_subplot(1,1,1)
sns.heatmap(cm, annot=True, fmt=".3f", linewidths=.5, square = True, cmap = 'Pastel2_r')
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.setp(cm_char.get_xticklabels(),visible=False)
plt.setp(cm_char.get_yticklabels(),visible=False)
plt.tick_params(axis='both', which='both', length=0)
title = f'Accuracy: {round(acc,2)} %'
plt.title(title, size = 15)
plt.show()
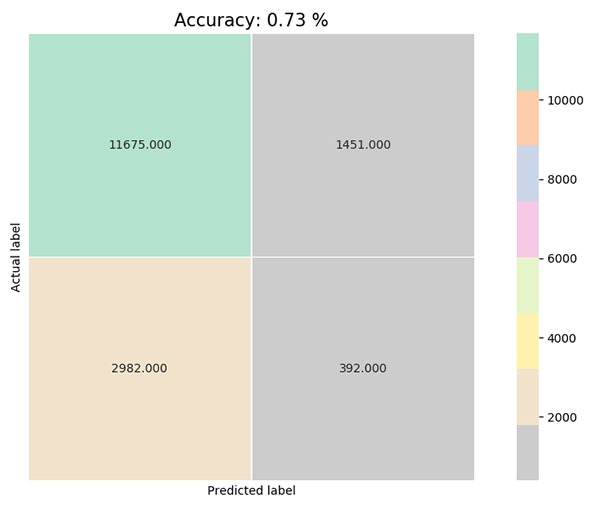
Bueno, con un 73% de accuracy, el modelo es más bien ‘normalito’.
Vamos a utilizar el módulo statmodels para, con los mismos datos, crear un modelo logístico y obtener los coeficientes, para ver si coinciden con los que ha calculado nuestro modelo.
lr = sm.Logit(y_train,X_train) result = lr.fit() print (result.summary2())
Optimization terminated successfully.
Current function value: 0.557941
Iterations 5
Results: Logit
=================================================================
Model: Logit No. Iterations: 5.0000
Dependent Variable: y Pseudo R-squared: -0.116
Date: 2018-09-23 09:39 AIC: 37390.0763
No. Observations: 33500 BIC: 37423.7535
Df Model: 3 Log-Likelihood: -18691.
Df Residuals: 33496 LL-Null: -16755.
Converged: 1.0000 Scale: 1.0000
-------------------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
-------------------------------------------------------------------
f1 -0.1794 0.0041 -44.2316 0.0000 -0.1874 -0.1715
f2 0.0690 0.0039 17.8527 0.0000 0.0614 0.0765
f3 -0.1691 0.0040 -41.8946 0.0000 -0.1771 -0.1612
f4 0.0666 0.0039 17.2582 0.0000 0.0590 0.0741
=================================================================
Aunque nuestro modelo puede mejorar clasificando, los coeficientes de la regresión logística si que los calcula bastante bien.
[table id=1 /]
¡Anímate y prueba con tu propio dataset!
Puedes descargarte el código de mi ![]()



