
Llevo unos días buscando un dataset para probar un algoritmo de clasificación. No encuentro ninguno que me convenza al 100%, así que he decidio construirme uno.
Ya hice algo parecido en mi post Cómo entrenar a tu perceptrón, utilizando para ello la función make_blobs, incluida en la librería de machine learning de Python scikit-learn.
La función make_blobs no es la única. El módulo datasets de scikit-learn, nos ofrece un montón de funciones que incluyen, además de cargar un dataset predeterminado, poder generar un dataset completamente nuevo.
Sin embargo, yo estaba buscando algo más…personalizado.
No veo por qué hay que ceñirse a ciertas librerías, siempre puedes encontrar tu propia solución si no te convence el resultado.
Así que me he hecho una funcioncita de forma rápida, que me permite crear un dataset con n características y una variable de respuesta que puede pertenecer a dos clases.
El código es el siguiente:
def genDataset(n_features = 4, n_samples = 1000, low = 0, high = 10, weights = [0.25, 0.25, 0.25, 0.25], threshold = 5):
"""
The function generates a random dataset with n predictor features and the result. The result
can take two values, zero and one. The result depends on the threshold.
:param n_features: Number of features.
:param n_samples: Number of samples.
:param low: The lowest value for the range of random values.
:param high: The highest value for the range of random values.
:param weight: List of the weights for each feature. There must be a weight for each feature.
:param threshold: It is the value that marks the limit to assign zero or one to the result.
:return: Dataframe
"""
import pandas as pd
import numpy as np
if len(weights) == n_features:
randomData = np.random.randint(low = low, high = high , size=(n_samples, n_features))
weights_m = np.asarray([weights]*n_samples)
p = np.array([1 if sum(row) >= threshold else 0 for row in randomData * weights_m])
res = pd.DataFrame(data=np.column_stack((randomData, p)),
columns = ['feat_%s_%s' %(str(i), str(w)) for i, w in enumerate(weights)]+['result_thr_%s'%threshold])
if sum(weights) != 1.0:
print ("Beware. The sum of the weights is different from 1.0: %f" %sum(weights))
return res
else:
print ("There must be a weight for each feature. Please, check the weights matrix.")
El corazón de genDataset es la función randint incluida en el módulo random de Numpy. Ésta función nos permite generar números aleatorios, a partir de una distribución uniforme de valores discretos, proporcionándole como argumentos el valor mínimo y el valor máximo de un intervalo. Además te permite crear arrays de varias dimensiones a través del argumento size.
Como argumentos, la función genDataset toma el número de variables explicativas que queremos generar (n_features), el número de muestras (n_samples) y el valor mínimo y el máximo anteriormente comentados.
Para crear la columna que etiquete con una clase a la muestra correspondiente, simplemente he añadido a la función otros dos argumento: weights y threshold.
Weights tendría el formato de una lista, con el peso correspondiente a cada variable explicativa. Y threshold, pues eso, es un límite. ¿Para qué sirven?. Para cada muestra se realiza la operación de multiplicar cada variable por su peso correspondiente, y se obtiene su suma. Si éste valor es mayor, o igual, que el threshold, la muestra se etiqueta como 1, y si no, como 0. Así obtenemos la columna para la variable etiqueta.
Vamos a probarla.
Voy a pedirle a la función que me genere un sample se 100000 muestras, entre el 0 y el 10, con 4 variables explicativas y unos pesos [0.125, 0.375, 0.375, 0.125], y un valor para el threshold de 6.
data = genDataset(n_features = 4, n_samples = 100000, low = 0, high = 10, weights = [0.125, 0.375, 0.375, 0.125], threshold = 6)
Podemos examinar un poco los datos.
data.head() feat_0_0.125 feat_1_0.375 feat_2_0.375 feat_3_0.125 result_thr_6 0 4 9 7 9 1 1 6 7 7 4 1 2 1 3 5 8 0 3 4 3 3 6 0 4 7 9 9 9 1
data.describe()
feat_0_0.125 feat_1_0.375 feat_2_0.375 feat_3_0.125 \
count 100000.000000 100000.000000 100000.000000 100000.00000
mean 4.495400 4.492530 4.500230 4.48148
std 2.880813 2.870834 2.866284 2.86885
min 0.000000 0.000000 0.000000 0.00000
25% 2.000000 2.000000 2.000000 2.00000
50% 4.000000 5.000000 5.000000 4.00000
75% 7.000000 7.000000 7.000000 7.00000
max 9.000000 9.000000 9.000000 9.00000
result_thr_6
count 100000.000000
mean 0.197610
std 0.398198
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 1.000000
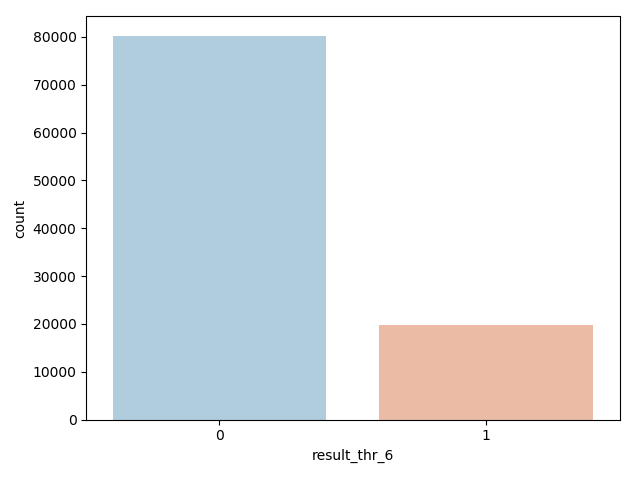
data.groupby('result_thr_6').size()
result_thr_6
0 80239
1 19761
dtype: int64
one_p = data.groupby('result_thr_6').size()[1]/data.groupby('result_thr_6').size()[0] * 100
one_p
24.627674821470855
sns.countplot(x='result_thr_6', data=data, palette = 'RdBu_r')
¡Ahora ya podemos utilizar estos datos para practicar con algún modelo de Machine Learning!.
Puedes descargarte el código de mi ![]()




