El pasado fin de semana estuve leyendo sobre Selenium, y se me ocurrió una idea para un nuevo post.
El tema iba de hacer un ejemplo con un modelo de Machine Learning. Y claro, necesitaba unos datos que tuvieran relación con la temática del artículo.
Como primer paso, necesitaba nombres del universo Star Wars.
Así que estuve buscando por Internet un generador de nombres. Una simple búsqueda en Google y aparecen unos cuantos. El problema que me encontré es que la mayoría te generan nombres de uno en uno. Hasta que di con este:
The Star Wars Random Name Generator
En esta web puedes elegir si quieres nombres masculinos, femeninos o de ambos. Y lo mejor, la cantidad. Hasta 100 nombres haciendo un simple click.
Oh, oh, problema. ¿Cómo leches hago ese simple click?
Pues aquí entra en juego Selenium, y no, no es el elemento químico.
Selenium es una herramienta para automatizar pruebas en aplicaciones web. Selenium lo integran varios componentes. El que vamos a utilizar nosotros se llama Selenium WebDriver. Con él podemos realizar acciones como si fueramos un usuario que está navegando por la web, pero de manera automática. Para poder utilizar la potencia de Selenium WebDriver debemos instalar el controlador correspondiente al navegador con el que vayamos a realizar las acciones. Nosotros utilizaremos Mozilla Firefox. Además, deberemos instalar el paquete de Selenium para Python.
La instalación de el driver puede resultar un poco confusa. Lo voy a explicar para Windows, para Ubuntu es similar. Primero tienes que descargarte el driver del navegador que vayas a utilizar. Nosotros, como he dicho antes, utilizaremos el driver para Firefox. Viene en un archivo comprimido. Descomprimes, y el archivo .exe (en Windows) lo colocas en la carpeta que te parezca bien, y te copias la ruta.
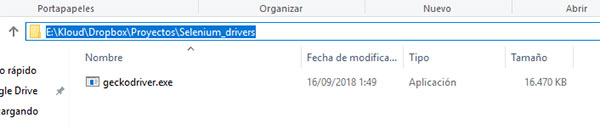
A continuación, añadimos a nuestra variable de sistema llamada Path, una nueva entrada, con la ruta al archivo.
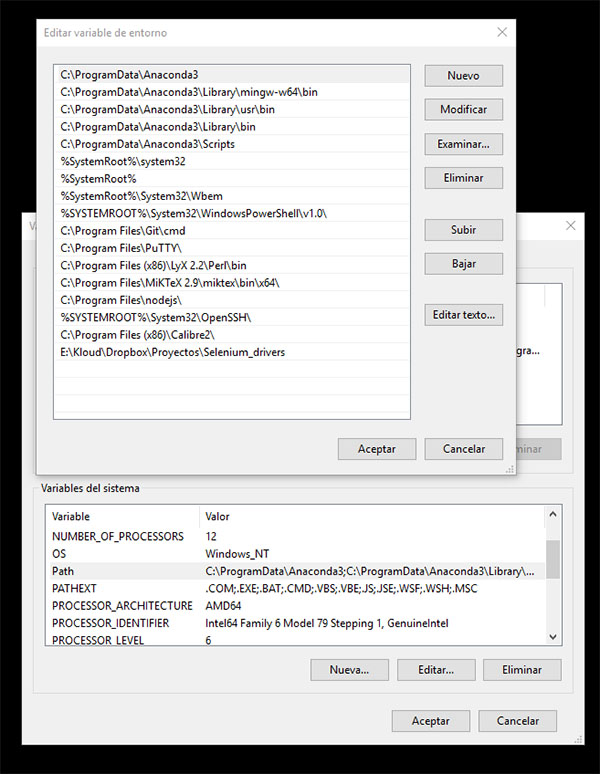
Y ya casi estaría. Solo quedaría instalar el paquete de selenium para python, algo tan sencillo como hacer, por ejemplo:
pip install selenium
Así pues, con la ayuda de Selenium y BeautifulSoup, vamos a ‘escrapear’ 100000 nombres del mundo Star Wars.
La url que vamos a atacar tiene esta pinta:
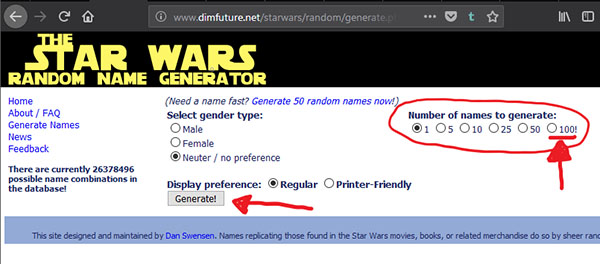
Examinando el código html, podemos ver que los elementos que activar son:
- El radio button con valor 100, que tiene como propiedades name = “choice y value=”100”.
- El botón Generate!, que tiene como propiedades name=”submit” y value=”Generate!”.
Con éstas propiedades podremos identificar los objetos y lanzar acciones sobre ellos.
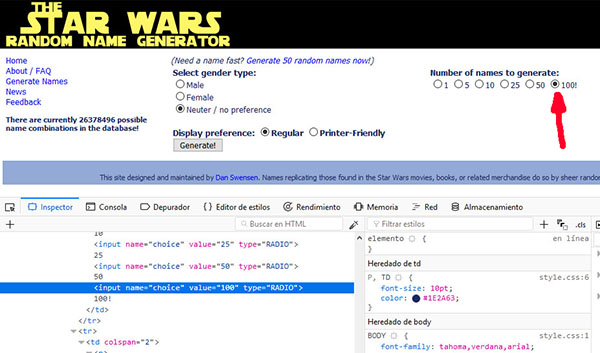
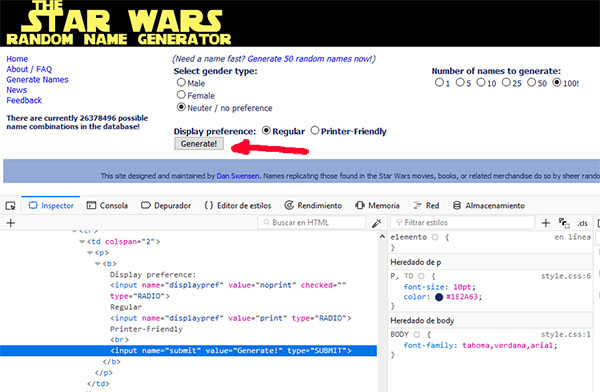
Para buscar los elementos a través del código html, utilizaremos la función find_element_by_xpath que nos proporciona Selenium Driver, y a la que le pasaremos como parámetros las propiedades de los objetos.
Una vez encontrado el objeto, utilizaremos la función click.
Al hacer click en el botón Generate!, se crea una tabla con los nombres. Haremos un scraping para obtener los nombres de la tabla utilizando BeautifulSoup, como ya hicimos aquí.
Resumiendo, el script realizará un loop, en el que Selenium automatizará el siguiente proceso:
- Selecciona la opción de 100 nombres.
- Hace click en el botón Generate.
Y gracias a BeautifulSoup captaremos los nombres de la tabla generada y los iremos añadiendo a una lista, evitando repeticiones. A continuación, pasaremos la lista a un dataframe y lo guardaremos en un csv.
El código quedaría así:
import pandas as pd
from selenium import webdriver
from bs4 import BeautifulSoup
from datetime import datetime
start_time = datetime.now()
print (f'Start time: {start_time}')
driver = webdriver.Firefox()
url = 'http://www.dimfuture.net/starwars/random/generate.php'
driver.get(url)
names = []
while len(names)<100000:
try:
#Click on Radio button with value 100
one_hundred = driver.find_element_by_xpath("//input[@name='choice' and @value='100']")
one_hundred.click()
#Click on Generate! button
generate = driver.find_element_by_xpath("//input[@name='submit' and @value='Generate!']")
generate.click()
#Transfer info to BeautifulSoup
starwars_names_soup = BeautifulSoup(driver.page_source, 'lxml')
table = starwars_names_soup.find_all('table')
rows = table[3].find_all("td")
for row in rows:
newname = row.get_text().strip().replace(u'\xa0', u' ')
if newname not in names:
names.append([newname])
except:
pass
print(len(names))
driver.close()
starwars_names_df = pd.DataFrame(names, columns = ['name'])
now = datetime.now()
filename = f'starwars_names_{now.year}{now.month}{now.day}.csv'
starwars_names_df.to_csv(filename, sep = ';', index = False, encoding = 'utf-8')
end_time = datetime.now()
print (f'End time: {end_time}')
total_time = end_time - start_time
print (f'Finished in: {total_time}')
#Finished in: 1:43:59.618806
Como podéis observar, le llevó una hora y tres cuartos finalizar el proceso.
Además, ya que estaba, me puse a ‘escrapear’ también los planetas y las razas del universo Star Wars.
Los planetas los he ‘escrapeado’ de esta web, y con este script:
import pandas as pd
import requests
from bs4 import BeautifulSoup
from datetime import datetime
start_time = datetime.now()
print (f'Start time: {start_time}')
starwars_planet_list= []
url_planets = 'http://starwars.wikia.com/wiki/List_of_planets'
url_planets_req = requests.get(url_planets)
planets_html = url_planets_req.text
planets_soup = BeautifulSoup(planets_html, "html.parser")
tables = planets_soup.find_all("tr")
for t, table in enumerate(tables):
for i, value in enumerate(table.find_all("td")):
if i == 0 and t >= 6:
starwars_planet_list.append([value.get_text().strip()])
starwars_planets_df = pd.DataFrame(starwars_planet_list, columns = ['name'])
now = datetime.now()
filename = f'starwars_planets_{now.year}{now.month}{now.day}.csv'
starwars_planets_df.to_csv(filename, sep = ';', index = False, encoding = 'utf-8')
end_time = datetime.now()
print (f'End time: {end_time}')
total_time = end_time - start_time
print (f'Finished in: {total_time}')
#Finished in: 0:00:00.437466
Y las razas las he obtenido de estas 5 webs: 1, 2, 3, 4, 5. Y este es el script:
import pandas as pd
import requests
from bs4 import BeautifulSoup
from datetime import datetime
species_urls = ['https://en.wikipedia.org/wiki/List_of_Star_Wars_species_(A%E2%80%93E)',
'https://en.wikipedia.org/wiki/List_of_Star_Wars_species_(F%E2%80%93J)',
'https://en.wikipedia.org/wiki/List_of_Star_Wars_species_(K%E2%80%93O)',
'https://en.wikipedia.org/wiki/List_of_Star_Wars_species_(P%E2%80%93T)',
'https://en.wikipedia.org/wiki/List_of_Star_Wars_species_(U%E2%80%93Z)']
start_time = datetime.now()
print (f'Start time: {start_time}')
def parse_species(url):
species_list = []
url_species_req = requests.get(url)
species_html = url_species_req.text
species_soup = BeautifulSoup(species_html, "html.parser")
species = species_soup.find_all("span", {'class': 'toctext'})
for specie in species:
name = specie.get_text().strip()
if name not in ('References', 'External links', 'Bibliography'):
species_list.append([name])
return species_list
starwars_species_list = []
for url in species_urls:
species_sublist = parse_species(url)
starwars_species_list += species_sublist
starwars_species_df = pd.DataFrame(starwars_species_list, columns = ['name'])
now = datetime.now()
filename = f'starwars_species_{now.year}{now.month}{now.day}.csv'
starwars_species_df.to_csv(filename, sep = ';', index = False, encoding = 'utf-8')
end_time = datetime.now()
print (f'End time: {end_time}')
total_time = end_time - start_time
print (f'Finished in: {total_time}')
#Finished in: 0:00:02.234633
Os dejo a vosotros investigar qué hacen los scripts para obtener los planetas y las razas.
Ahora a preparar el post donde utilizaré toda esta info ‘scrapeada’.
¡Estad atentos!
Puedes descargarte el código de mi ![]()