
¿Y si quisiéramos evolucionar nuestro perceptrón, haciéndolo algo más ‘inteligente’?. Excepto algunas personas con las que la evolución ha fracasado estrepitosamente, eso es lo que llevamos haciendo miles de millones de años. Una evolución del Perceptrón es ADALINE, Adaptative Linear Neuron.
En 1960 Bernard Widrow y Marcian Hoff publicaron ‘An Adaptative “Adaline” Neuron using chemical “memistors”‘, donde describen cómo, utilizando circuitos resistivos con memoria, el sistema puede aprender de forma automática, cambiando su propia estructura para mejorar su rendimiento, teniendo en cuenta sus experiencias anteriores.
La principal diferencia con el modelo del Perceptrón, es que, mientras en éste, la función de activación era una función escalón, en Adaline la función de activación es una función lineal. Ahora utilizaremos el valor de salida de la función lineal para ir calculando el error e ir actualizando los pesos.
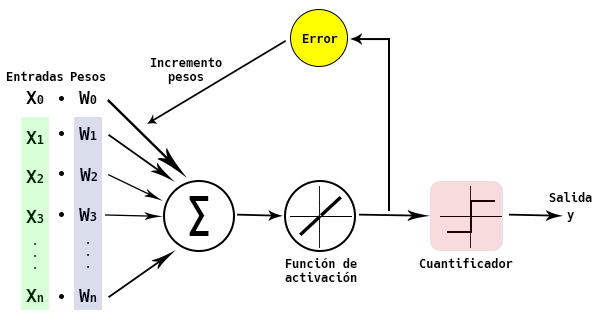
Nuestra función de entrada, z, sigue siendo el producto de las entradas por los pesos:
![\[ z = \sum_{i=0}^{n} x_{i}w_{i} = x_{0}w_{0} + x_{1}w_{1} + \cdots + x_{n}w_{n} = \mathbf{w}^{T}\mathbf{x} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-3ae1615611ffdf58af4d15df18540b91_l3.png "Rendered by QuickLaTeX.com")
Nuestra función de activación será:
![\[ \varphi(z)=\varphi(\mathbf{w}^{T}\mathbf{x}) = \mathbf{w}^{T}\mathbf{x}\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-cf959b665a6f6d9ea0620443d577bf4b_l3.png "Rendered by QuickLaTeX.com")
y la utilizaremos para actualizar los pesos.
La función cuantificador nos servirá para predecir a qué clase pertenece cada muestra.
Adaline sigue siendo una red neuronal de una sola capa, y tiene la misma limitación que el perceptron, ya que únicamente puede resolver problemas linealmente separables.
Otra diferencia importante con respecto al Perceptrón, es que con Adaline se actualizan todos los pesos de todas las muestras del conjunto de datos a la vez en cada iteración.
El algoritmo de aprendizaje que utiliza Adaline es conocido como la regla de Widrow-Hoff, en la que se busca minimizar la función que calcula el error entre la entrada y el valor real.
Para el cálculo de dicho error se utiliza el Error Cuadrático Medio.
Y para minimizarlo se utiliza el método de Descenso por Gradiente o Gradient Descent, del que hablé en mi post: Beam me up, Gradient Descent!.
Así pues, iremos actualizando los pesos utilizando el gradiente de la función de costo y una tasa de aprendizaje (η) que tendremos que elegir.
Si nuestra función de costo es:
![\[ J= \frac{1}{2}\sum_{i=1}^n (y_{i}- \hat{y}_{i})^{2} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-a808ae6e3a400df3cbd136c053b313b1_l3.png "Rendered by QuickLaTeX.com")
El gradiente de dicha función nos quedará:
![\[ \frac{\partial J}{\partial w_{j}} = \frac{\partial }{\partial w_{j}}\left ( \frac{1}{2}\sum_{i}^{ } \left ( \delta_{i} - \varphi(z_{i}) \right )^{2}\right )\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-cd2f1fd6a1b20f62dfd1193ef63d3027_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{\partial J}{\partial w_{j}} = - \sum_{i}^{ }\left ( \delta_{i} -\varphi(z_{i} \right )x_{ij}\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-0f94e5f65f48acd37a2b8e129c36c3a0_l3.png "Rendered by QuickLaTeX.com")
Y por lo tanto, para el incremento de los pesos tendremos:
![\[\Delta w_{n} = - \eta\nabla J(w) = \eta\sum_{i}^{ }\left ( \delta_{i} -\varphi(z_{i} \right )x_{ij}\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-3a59c673d6c4d1083ee6a88ff472bf65_l3.png "Rendered by QuickLaTeX.com")
Los pasos del algortimo son los siguiente:
- Al comienzo del algoritmo se escoge un valor aleatorio, cercano a cero, para los pesos. Se elige una tasa de aprendizaje entre 0 y 1. Se elige el número de iteraciones (epochs) que realizará el algoritmo. Se podría decir al algoritmo que parara al llegar a un cierto valor de la función de coste. Pero lo que haremos es ir haciendo pruebas con el número de iteraciones y la tasa de aprendizaje. Después de cada prueba dibujaremos el valor de la función de coste con respecto al número de iteración, para comprobar cómo se va ajustando el modelo. Dicho valor deberá disminuir con cada iteración, hasta alcanzar un mínimo.
- Calculamos nuestra función z, esto es, el sumatorio de los productos de las entradas por sus pesos.
- Calculamos los errores entre lo que resulta de nuestra función z y las salidas esperadas.
- Actualizamos los pesos. Así, en cada iteración, los pesos se verán actualizados de la siguiente forma:
![\[w = w + \Delta w\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-cc630e1f972f0dcb8ed573f1a7a0472a_l3.png "Rendered by QuickLaTeX.com")
Bien! Ahora que ya tenemos claro cómo funciona el algoritmo, vamos a meternos en harina.
Como siempre, primero los datos. Vamos a probar con dos dataset distintos. El primero será el mismo que utilizamos en el modelo del Perceptrón. Y también probaremos con otro dataset creado de la misma manera que el del Perceptrón. Te puedes descargar ambos aquí.
Empezamos importando las librerías que vamos a necesitar.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap import seaborn as sns from sklearn.model_selection import train_test_split from sklearn import metrics
Importamos los datos y vemos qué pinta tienen.
df_adaline = pd.read_csv('adaline_data.csv', sep=';')
df_perceptron = pd.read_csv('perceptron_data.csv', sep=';')
datasets = [df_adaline, df_perceptron]
datanames = ['df_adaline', 'df_perceptron']
X_a = df_adaline.iloc[:, [0, 1]].values
y_a = df_adaline.iloc[:, 2].values
X_p = df_perceptron.iloc[:, [0, 1]].values
y_p = df_perceptron.iloc[:, 2].values
colors = ['#D7D98E', '#91CFEA']
palette = sns.color_palette(colors)
cmap = ListedColormap(colors)
plt.figure(figsize=(15, 12))
plt.subplot(221)
plt.title('ADALINE DATA')
plt.scatter(X_a[:, 0], X_a[:, 1], marker='o',c=y_a,
s=25, edgecolor='k', cmap = cmap)
plt.xlabel('feature 1')
plt.ylabel('feature 2')
plt.subplot(222)
plt.title('PERCEPTRON DATA')
plt.scatter(X_p[:, 0], X_p[:, 1], marker='o', c=y_p,
s=25, edgecolor='k', cmap=cmap)
plt.xlabel('feature 1')
plt.ylabel('feature 2')
plt.subplot(223)
sns.countplot(df_adaline['type'],label='count', palette = palette)
plt.subplot(224)
sns.countplot(df_perceptron['type'],label='count', palette = palette)
plt.show()

Podemos sacar una tabla resumen de las características de los datos, mediante la siguiente función. Es la función describe para dataframes de Pandas, a la que he añadido la cuenta de valores nulos, la cuenta de los valores únicos, la moda y la desviación típica por característica.
def describe_plus(df):
"""
:param df: dataframe
"""
describe = df.describe()
describe.loc['NaNs'] = [df[feature].isnull().sum() for feature in df.columns]
describe.loc['uniques'] = [len(df[feature].unique()) for feature in df.columns]
describe.loc['mode'] = [df[feature].mode()[0] for feature in df.columns]
describe.loc['std'] = [df[feature].std() for feature in df.columns]
return describe
describe_plus(df_adaline)
feature1 feature2 type
count 1000.000000 1000.000000 1000.0000
mean 5.492163 3.987897 0.0000
std 0.816540 3.056058 1.0005
min 2.345508 -1.561490 -1.0000
25% 4.912803 1.008180 -1.0000
50% 5.508613 4.110000 0.0000
75% 6.091449 6.935053 1.0000
max 7.668161 8.823115 1.0000
NaNs 0.000000 0.000000 0.0000
uniques 1000.000000 1000.000000 2.0000
mode 2.345508 -1.561490 -1.0000
describe_plus(df_perceptron)
feature1 feature2 type
count 1000.000000 1000.000000 1000.0000
mean 3.606442 3.883439 0.0000
std 0.816540 3.056058 1.0005
min -4.831269 -2.290611 -1.0000
25% -0.778176 2.287451 -1.0000
50% 3.339908 3.816354 0.0000
75% 7.970958 5.482050 1.0000
max 12.142749 9.609528 1.0000
NaNs 0.000000 0.000000 0.0000
uniques 1000.000000 1000.000000 2.0000
mode 2.345508 -1.561490 -1.0000
Vamos a preparar un poco los datos, normalizando todas las características de los dataframes al mismo rango. El uso de ésta técnica es frecuente en métodos de Machine Learning, y permite un mejor comportamiento de los algoritmos. Gradient Descent es uno de los algoritmos a los que sienta bien realizar un escalado previo de los datos. Sin embargo, hay que utilizar estas técnicas con cuidado, ya que un mal uso puede dar al traste con tus datos y en consecuencia con tu modelo.
Para normalizar los datos utilizaremos la normalización estandar, que consiste en, a cada muestra de nuestros datos, restarle la media y dividir el resultado por la desviación típica:
![\[ Xnorm_{i} = \frac{x_{i} - \overline{x}_{i}}{\sigma_{i}}\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-fcb3e19516d478de1df9b36308d68b8f_l3.png "Rendered by QuickLaTeX.com")
Después de aplicar la normalización a los dos dataframes, df_perceptron y df_adaline, vamos a dividir los datos en datos de entrenamiento y datos de prueba. A continuación, meteremos éstos en un diccionario que llamaremos train_test_data, en el que la clave será el nombre del dataframe y los valores los obtenidos después de usar el la función train_test_split del módulo model_selection de scikit-learn.
Lo haremos así:
train_test_data = {}
for index, dataset in enumerate(datasets):
X = dataset.iloc[:, [0, 1]].values
y = dataset.iloc[:, 2].values
# normalizamos
X_std = np.copy(X)
X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
X_std[:,1] = (X[:,1] - X[:,1].mean()) / X[:,1].std()
# Dividimos los dataset en datos de entrenamiento y de prueba
X_train, X_test, y_train, y_test = train_test_split(X_std, y, test_size=0.3)
# Los añadimos al diccionario
train_test_data[datanames[index]] = {"X_train": X_train, "X_test": X_test, "y_train": y_train, "y_test": y_test}
plt.title('%s | Normalizado'%datanames[index])
plt.scatter(X_std[:, 0], X_std[:, 1], marker='o',c=y,
s=25, edgecolor='k', cmap = cmap)
plt.xlabel('feature 1')
plt.ylabel('feature 2')
plt.show()

Vale. Ahora que ya tenemos los datos preparados, vamos a por nuestro modelo. Para ellos crearemos una clase que llamaremos Adaline. Lo primero será ‘construir’ la clase con el método __init__ , en el que pondremos como parámetros de entrada la tasa de aprendizaje y el número de iteraciones:
class Adaline_k():
def __init__(self, eta=0.0001, n_iter=50):
"""
:param eta: tasa de aprendizaje
:param n_iter: número de iteraciones(epochs)
"""
self.eta = eta
self.n_iter = n_iter
Lo siguiente será añadir un método, al que vamos a llamar zeta que nos calcule el valor de la función z, esto es, el producto de las características por sus pesos:
class Adaline_k():
def __init__(self, eta=0.0001, n_iter=50):
"""
:param eta: tasa de aprendizaje
:param n_iter: número de iteraciones(epochs)
"""
self.eta = eta
self.n_iter = n_iter
def zeta(self, X):
"""
Calcula el producto de las entradas por sus pesos
:param X: datos de entrenamiento con las caracteristicas. Array
"""
res = np.dot(1, self.weights[0]) + np.dot(X, self.weights[1:])
return res
También añadimos la función de activación, que en nuestro caso hemos dicho que tomará el mismo valor que zeta:
class Adaline_k():
def __init__(self, eta=0.0001, n_iter=50):
"""
:param eta: tasa de aprendizaje
:param n_iter: número de iteraciones(epochs)
"""
self.eta = eta
self.n_iter = n_iter
def zeta(self, X):
"""
Calcula el producto de las entradas por sus pesos
:param X: datos de entrenamiento con las caracteristicas. Array
"""
res = np.dot(1, self.weights[0]) + np.dot(X, self.weights[1:])
return res
def activacion(self, X):
"""
Función lineal de activacion. En este caso sera la misma que zeta
"""
return self.zeta(X)
Ahora vamos a añadir el método fit, que se encargará de ir comprobando los errores, actualizar los pesos y calcular el valor de la función de coste:
class Adaline_k():
def __init__(self, eta=0.0001, n_iter=50):
"""
:param eta: tasa de aprendizaje
:param n_iter: número de iteraciones(epochs)
"""
self.eta = eta
self.n_iter = n_iter
def zeta(self, X):
"""
Calcula el producto de las entradas por sus pesos
:param X: datos de entrenamiento con las caracteristicas. Array
"""
res = np.dot(1, self.weights[0]) + np.dot(X, self.weights[1:])
return res
def activacion(self, X):
"""
Función lineal de activacion. En este caso sera la misma que zeta
"""
return self.zeta(X)
def fit(self, X, y):
#Generamos pesos iniciales aleatorios
self.weights = np.random.random_sample((X.shape[1] + 1,))
#Creamos dos listas para añanir el valor de la funcion de coste
#y el número de iteración
self.iters = []
self.coste = []
#Comenzamos las iteraciones (epochs)
for iter in range(self.n_iter):
#Calculamos el producto de las entradas por sus pesos, esto es,
#la función zeta
zeta = self.zeta(X)
#Calculamos los errores entre las salidas obtenidas y las esperadas
errors = (y - zeta)
#Actualizamos los pesos
self.weights[1:] += self.eta * X.T.dot(errors)
self.weights[0] += self.eta * errors.sum()
#Calculamos el valor de la funcion de coste
coste = 0.5*np.power(errors, 2).sum()
#Guardamos el valor del guardiente de la funcion de coste
#y tambien guardamos el número de iteración (epoch)
self.coste.append(coste)
self.iters.append(iter)
print ('Modelo Adaline_k entrenado correctamente:')
print ('pesos finales: %s' %str(self.weights))
print ('coste: %s' %str(self.cost))
Por último, añadimos el método predict, que será el encargado de clasificar en función del valor de la función de activación:
class Adaline_k():
def __init__(self, eta=0.0001, n_iter=50):
"""
:param eta: tasa de aprendizaje
:param n_iter: número de iteraciones(epochs)
"""
self.eta = eta
self.n_iter = n_iter
def zeta(self, X):
"""
Calcula el producto de las entradas por sus pesos
:param X: datos de entrenamiento con las caracteristicas. Array
"""
res = np.dot(1, self.weights[0]) + np.dot(X, self.weights[1:])
return res
def activacion(self, X):
"""
Función lineal de activacion. En este caso sera la misma que zeta
"""
return self.zeta(X)
def fit(self, X, y):
#Generamos pesos iniciales aleatorios
self.weights = np.random.random_sample((X.shape[1] + 1,))
#Creamos dos listas para añanir el valor de la funcion de coste
#y el número de iteración
self.iters = []
self.coste = []
#Comenzamos las iteraciones (epochs)
for iter in range(self.n_iter):
#Calculamos el producto de las entradas por sus pesos, esto es,
#la función zeta
zeta = self.zeta(X)
#Calculamos los errores entre las salidas obtenidas y las esperadas
errors = (y - zeta)
#Actualizamos los pesos
self.weights[1:] += self.eta * X.T.dot(errors)
self.weights[0] += self.eta * errors.sum()
#Calculamos el valor de la funcion de coste
coste = 0.5*np.power(errors, 2).sum()
#Guardamos el valor del guardiente de la funcion de coste
#y tambien guardamos el número de iteración (epoch)
self.coste.append(coste)
self.iters.append(iter)
print ('Modelo Adaline_k entrenado correctamente:')
print ('pesos finales: %s' %str(self.weights))
print ('coste: %s' %str(self.coste))
def predict(self, X):
"""
Calcula la salida de la neurona teniendo en cuenta la función de activación
:param X: datos con los que predecir la salida de la neurona. Array
:return: salida de la neurona
"""
return np.where(self.activacion(X) >= 0.0, 1, -1)
Con esto ya tendríamos la clase Adaline preparada. Así que vamos al lío.
Vamos a entrenar el algoritmo con los dos dataset que tenemos. Después dibujaremos los datos clasificados y la región a la que pertenecen, y una gráfica del valor de la función de coste vs el número de iteración (epoch). Para dibujar los datos clasificados utilizaremos esta función, plot_decision_regions, que representará los datos de entrenamiento, las zonas de clasificación, y los datos de test.
def plot_decision_regions(X, y, classifier, X_test, y_test, resolution=0.02, test_idx=False):
markers = ('s', 'x')
colors = ['#D7D98E', '#91CFEA']
palette = sns.color_palette(colors)
cmap = ListedColormap(colors)
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.2, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=1, c=cmap(idx),
marker=markers[idx], label='%s | train set'%str(cl), linewidths=0.5,edgecolors= 'grey')
if test_idx:
cmap_test = ListedColormap(colors)
for idx, cl in enumerate(np.unique(y_test)):
plt.scatter(x=X_test[y_test == cl, 0], y=X_test[y_test == cl, 1],
alpha=1, c=cmap_test(idx), linewidths=0.8,
marker='o', label='%s | test set'%str(cl), edgecolors= 'black')
Además, evaluaremos el modelo, calculando la matriz de confusión, y algunas métricas como la Sensibilidad (Recall), Accuracy y Precisión, de las que hable en mi post: Matriz de confusión.
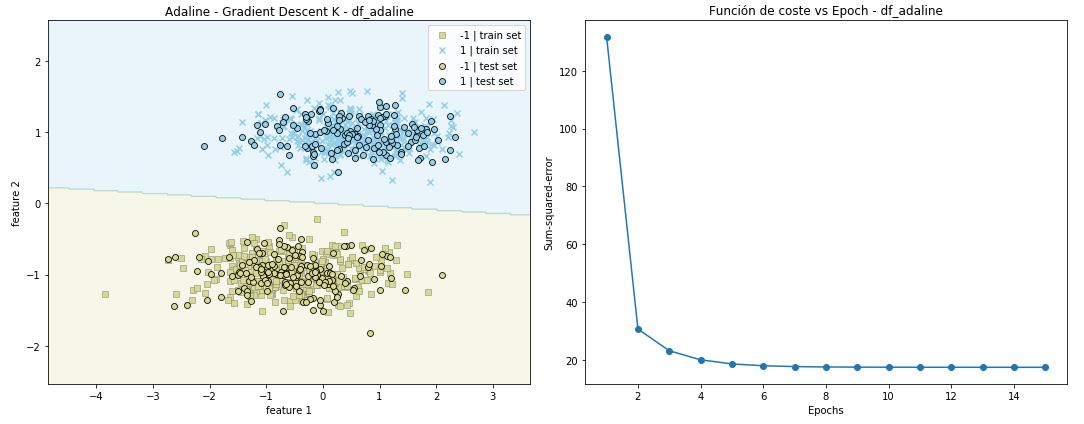
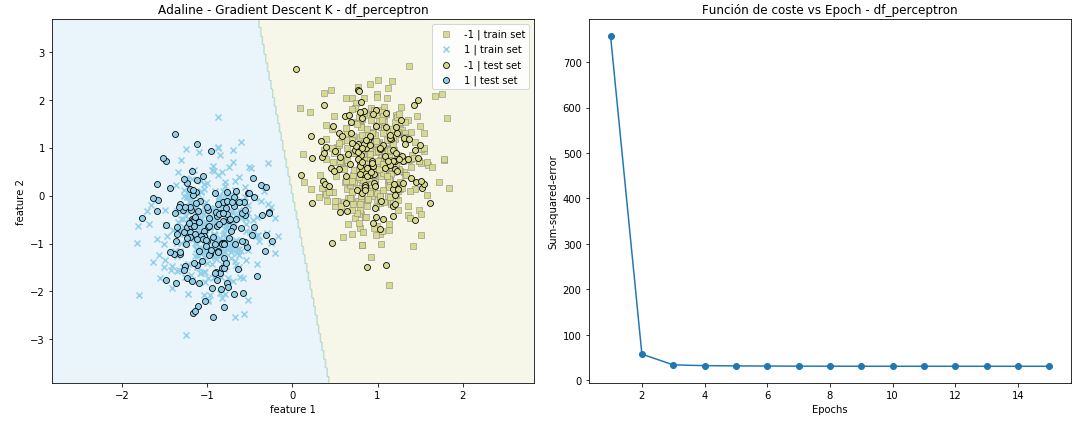
for index, dataset in enumerate(datasets):
print (datanames[index] + ' | '+'#'*50)
X = train_test_data[datanames[index]]['X_train']
y = train_test_data[datanames[index]]['y_train']
X_test = train_test_data[datanames[index]]['X_test']
y_test = train_test_data[datanames[index]]['y_test']
adaGDK = Adaline_k(n_iter=15, eta=0.001)
adaGDK.fit(X,y)
plt.figure(figsize=(15, 6))
plt.subplot(121)
plot_decision_regions(X, y, classifier=adaGDK, X_test = X_test, y_test=y_test, test_idx=True)
plt.title('Adaline - Gradient Descent K - %s' %datanames[index])
plt.xlabel('feature 1')
plt.ylabel('feature 2')
plt.legend(loc='upper right')
plt.subplot(122)
plt.plot(range(1, len(adaGDK.coste) + 1), adaGDK.coste, marker='o')
plt.title('Función de coste vs Epoch - %s' %datanames[index])
plt.xlabel('Epochs')
plt.ylabel('Sum-squared-error')
plt.tight_layout()
plt.show()
print ('EVALUANDO MODELO | ' + '#'*50)
print ('MATRIZ DE CONFUSION')
predicciones = adaGDK.predict(X_test)
cm = metrics.confusion_matrix(y_test, predicciones)
recall_score = metrics.recall_score(y_test, predicciones)
fig = plt.figure(figsize=(10,6))
cm_char = fig.add_subplot(1,1,1)
sns.heatmap(cm, annot=True, fmt=".3f", linewidths=.5, square = True, cmap = 'Pastel2_r')
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.setp(cm_char.get_xticklabels(),visible=False)
plt.setp(cm_char.get_yticklabels(),visible=False)
plt.tick_params(axis='both', which='both', length=0)
title = f'Recall Score: {recall_score}'
plt.title(title, size = 15)
plt.show()
print (f'Sensibilidad (Recall): {recall_score}')
acc_score = metrics.accuracy_score(y_test, predicciones)
print (f'Acccuracy score: {acc_score}')
precision = metrics.precision_score(y_test, predicciones)
print (f'Precision score: {precision}')
El código anterior muestra lo siguiente:
df_adaline | ################################################## Modelo Adaline_k entrenado correctamente: pesos finales: [-5.36257495e-05 4.39698001e-02 9.52957012e-01] coste: [131.69426028726704, 30.73242540601643, 23.234817810152713, 20.08968503071496, 18.678155652640513, 18.03945160247211, 17.749980584720447, 17.61874593619242, 17.55924561642617, 17.532268500939, 17.52003719588719, 17.514491573459257, 17.511977211257147, 17.510837209843878, 17.5103203379206]
EVALUANDO MODELO | ################################################## MATRIZ DE CONFUSION

Sensibilidad (Recall): 1.0 Acccuracy score: 1.0 Precision score: 1.0
df_perceptron | ################################################## Modelo Adaline_k entrenado correctamente: pesos finales: [ 0.00472021 -0.88525479 -0.09731476] coste: [757.7160958317447, 57.311281795481364, 33.621141168360055, 31.94939248093172, 31.366082087849602, 31.03148264217927, 30.830981005157362, 30.710400616031674, 30.63785641500621, 30.594209804955945, 30.567949397357168, 30.55214955067514, 30.542643407457355, 30.536923936698315, 30.533482757122542]
EVALUANDO MODELO | ################################################## MATRIZ DE CONFUSION
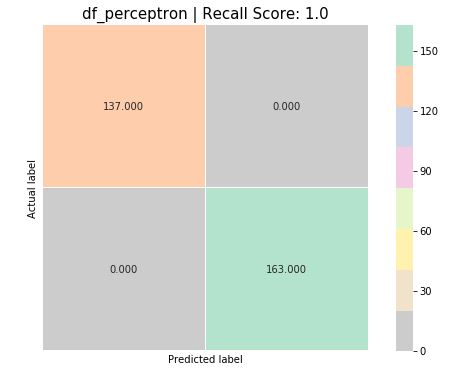
Sensibilidad (Recall): 1.0 Acccuracy score: 1.0 Precision score: 1.0
¡Oh!, tenemos un 100% de acierto sobre nuestros datos de test!. Y además el modelo necesita muy pocas iteraciones para converger!
Anímate y entrena con tus propios datos a Adaline!
Puedes descargarte el código de mi ![]()
Bibliografía: Python Machine Learning, Sebastian Raschka.




