
En un post anterior, hacía una pequeña introducción a las bases de datos orientadas a grafos, y hacía mención a una en concreto, Neo4j. La pregunta que viene ahora es, bien, ya tenemos los grafos en una base de datos, ¿cómo la manipulo? La respuesta es Neo4j’s graph query language , cypher para los amigos, que viene a ser cómo el SQL para las bases de datos relaciones. Veremos un poco los comandos básicos de cypher vs SQL.
El desarrollador de Neo4j tiene varias formas de interactuar con el motor de la base del datos utilizando cypher. Una de ellas es utilizar Neo4j Desktop, que es lo que SQL Developer a Oracle, o MSSQL Management Studio a MSSQLServer.
Desde Neo4j Desktop se pueden gestionar diferentes instancias de Neo, utilizar plugins, crear diferentes bases del datos e interactuar con ellas.
Otra forma más sencilla es utilizar Neo4j Browser, una interfaz web que te permite realizar consultas, visualizar los datos y modificarlos.
Otra manera, un poco menos cómoda (para gustos los colores), es comunicarse con la base de datos a través de la consola, utilizando cypher-shell, la herramienta por línea de comandos de Neo4j que te permite lanzar consultas y realizar algunas tareas de administración de la base de datos.
Cualquier opción de los entorno de desarrollo anteriores es válida. Y en todos ellos se utiliza cypher para interactuar con la base de datos.
SINTAXIS BÁSICA
Ya sabemos que en una base de datos orientada a grafos tenemos NODOS y RELACIONES. Pero…
- ¿Cómo representas un nodo en cypher?
Lo haces con los paréntesis (). En cypher representas un nodo como una variable entre paréntesis, dándole el nombre que prefiera, por ejemplo (k), (dios), (casa), etc… Funciona como en cualquier otro lenguaje de programación, pudiendo llamar a esta variable en otro momento de tu código cypher.
Puedes también definir la variable nodo sin un valor, utilizando únicamente los paréntesis de esta forma (). Este nodo puede hacer referencia a cualquier nodo dentro del grafo.
También puedes definir un nodo acotándolo por su tipo, utilizando las etiquetas de las que hablamos en el post anterior.
(d:DiosRomano), (:DiosRomano)
De este modo las búsquedas se limitan únicamente a ese tipo de nodos. Es un buena práctica utilizar esta notación para que las consultas tengan un mejor rendimiento.
() //anonymous node (no label or variable) can refer to any node in the database (d:DiosRomano) //using variable d and label DiosRomano (:Templo) //no variable, label Templo (god:Olympus) //using variable god and label Olympus
- ¿Cómo se representa una relación en cypher?
En cypher las relaciones se representan por medio de flechas -> <- que unen nodos. Las relaciones tienen un nombre, que se llama tipo, y pueden tener propiedades. Un ejemplo de notación podría ser este:
CREATE (t:Templo)-[:CULTO_A]->(d:DiosRomano)
Aquí os dejo un link a los conceptos básicos de cypher.
CYPHER vs SQL
Las 4 sentencias SQL más comunes que se utilizan sobre bases de datos relacionales son: SELECT, INSERT, UPDATE y DELETE. Veremos cuáles son sus equivalentes en cypher para comenzar a realizar consultas sencillas.
INSERT
Para manipular una base de datos relacional, en este caso introducir información, se utiliza la sentencia INSERT. Con ella puedes añadir registros en una tabla.
Un ejemplo de consulta INSERT sería el siguiente, con el que añadiríamos un nuevo registro en la tabla tabla_diosesRomamos con los siguientes valores en los campos correspondientes:
INSERT INTO tabla_diosesRomanos ( nombre, dominio) VALUES ('Marte', 'Guerra')
¿Cómo haríamos algo similar en Neo? Con la sentencia CREATE podemos añadir un nodo al grafo con la etiqueta DiosRomano y los atributos nombre y dominio.
CREATE (n:DiosRomano {nombre:'Marte', dominio:'Guerra'})

Si quisiéramos crear una relación entre dos nodos ya existentes en nuestra base de datos, lo podríamos hacer así. Primero buscaríamos los dos nodos a relacionar, y después crearíamos la relación entre ellos.
MATCH (a:DiosRomano),(b:DiosRomano) WHERE a.nombre = 'Juno' AND b.nombre = 'Marte' CREATE (a)-[r:MADRE_DE]->(b) RETURN a,b,r

SELECT
En SQL, la sentencia SELECT determina qué columnas de las diferentes tablas de tu modelo relacional deben estar incluidas en el conjunto de resultados de tu consulta.
Un ejemplo se esto sería una consulta sobre la tabla tabla_diosesRomanos, de la que queremos obtener los campos nombre y domino de las personas que se llaman Marte:
SELECT nombre, dominio FROM tabla_diosesRomanos WHERE nombre="Marte"
La sentencia equivalente a la sentencia SELECT en cypher es MATCH.
El equivalente a los nombres de columnas serían los atributos de los nodos.
La consulta SQL anterior en cypher tendría esta pinta:
MATCH (n:DiosRomano) WHERE n.nombre='Marte' RETURN n.nombre, n.dominio
MATCH (n:DiosRomano {nombre:'Marte'}) RETURN n.nombre, n.dominio

Como veis la sintaxis es similar, y muy muy intuitiva. La cosa se pone interesante cuando queremos información de un patrón con la relación entre dos nodos.
Imaginemos que queremos consultar templos dónde se rendía culto a Juno. En nuestra base de datos relacional existe una tabla en la que aparecen estos templos asociadas al nombre del dios.
La consulta que tendríamos que lanzar sería esta:
SELECT tdr.nombre, tt.nombre FROM tabla_diosesRomanos tdr JOIN tabla_templos tt ON tdr.nombre=tt.dios WHERE tdr.nombre="Juno"
Mientras que en cypher tendría esta pinta
MATCH (n:Templo)-[rel:CULTO_A]->(d:DiosRomano{nombre:"Juno"})
RETURN n.nombre, d.nombre
MATCH (n:Templo)-[rel:CULTO_A]->(d:DiosRomano)
WHERE d.nombre="Juno"
RETURN n.nombre, d.nombre
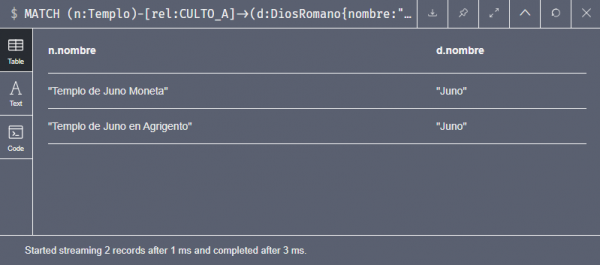
Mucho más sencilla en cypher que en SQL, y mucho más sencilla aún si quisiéramos aumentar el patrón con otra relación. En SQL se empezaría a complicar la cosa añadiendo JOINS. Esto en lo referente a la notación, pero si hablamos del rendimiento, la búsqueda del patrón en Neo4j es mucho más eficiente que la búsqueda de los datos en una base relacional, al tener ésta que recorrerse todas las tablas de los JOINS.
UPDATE
El comando UPDATE se utiliza en SQL para modificar registros en las tablas de tu base de datos. Por ejemplo, si quisiéramos cambiar el dominio de la diosa Juno, del matrimonio al amor, lanzaríamos la siguiente query:
UPDATE tabla_diosesRomanos SET domino='amor' WHERE nombre="Juno"
En cypher, el equivalente sería modificar el valor de las propiedades de algún nodo o relación. En el caso que hemos utilizado de ejemplo, sería lanzando esta query:
MATCH (n:DiosRomano { nombre: 'Juno' })
SET n.dominio = 'amor'
RETURN n.nombre, n.dominio

En ese caso la sintaxis es otra vez muy parecida e intuitiva.
DELETE
Y por último vamos a ver el comando DELETE, que en SQL se utiliza para eliminar registros de una tabla de tu base de datos.
Si por ejemplo quisiéramos eliminar al dios Marte de nuestra tabla de dioses lo haríamos así:
DELETE FROM tabla_diosesRomanos WHERE nombre="Juno"
Es una sintaxis sencilla y a la vez muy potente. ¡Ojo!, te puedes cargar una base de datos si no filtras bien lo que quieres borrar….No te olvides de poner el WHERE en el DELETE FROM…
El equivalente en cypher sería borrar nodos y relaciones. La sintaxis es muy parecida al SQL. Se pueden dar estas casuísticas:
- Borrar únicamente un nodo, en este caso el nodo del dios Marte:
MATCH (n:DiosRomano { name: 'Marte' })
DELETE n
- Borrar una relación, en este caso la relación MADRE_DE entre el nodo del dios Marte y el nodo de la diosa Juno:
MATCH (a.DiosRomano { nombre: 'Juno' })-[r:MADRE_DE]->(b.DiosRomano {nombre: 'Marte' })
DELETE r
- Borrar un nodo y todas sus relaciones, en este caso el nodo del dios Marte y todas sus relaciones:
MATCH (n.DiosRomano { nombre: 'Marte' })
DETACH DELETE n
- Y por último, borrar todos los nodos y relaciones. Esta consulta solo es útil para eliminar datasets pequeños, para borrar grandes cantidades de datos se utilizan otras técnicas que veremos en otros posts.
MATCH (n) DETACH DELETE n
Hasta aquí llega la introducción a los comandos básicos de cypher. Os dejo el link a todos los comandos que se pueden utilizar en cypher para la manipulación de la base de datos.
¡Os animo a practicar con ellos!
Nos vemos en el siguiente post, ¡Mucha fuerza! #YomeQuedoenCasa
Aprendizaje automático Aprendizaje supervisado Automation bases de datos Beautiful Soup Clasificador Classifier cypher Data Federation Data Sharding defaultdict Fabric Geocodificación Geoposicionamiento geopy Grafos Graph Databases groupby itemgetter itertools LEGO logistic regression Machine Learning Modbus neo4j neo4j v4 numpy Odds pandas Perceptrón Probabilidad Probability puesta en producción Python Qlik Regresión Regresión lineal regresión logística Regression SCADA Scikit-learn Selenium Supervised learning Visualización Web Scraping




