
Hoy quería hacer una introducción rápida sobre el algoritmo Gradient Descent, antes de seguir usando modelos de Machine Learning en mis siguientes posts.
¿Y por qué escribir sobre esto? La respuesta es muy sencilla: Gradient Descent es un algoritmo que se encuentra en las entrañas de un montón de sistemas de Inteligencia Artificial y es crucial dentro del campo del Machine Learning.
Gradient Descent hace lo siguiente: Al pasarle una función, coge y busca el punto donde ésta alcanza su valor mínimo.
Hasta aquí fácil. ¿Pero qué función le pasamos? Aquí entra en juego el concepto de función de coste, término heredado de la ciencia económica. En Machine Learning, una función de coste es aquella que nos da una medida de cómo de bien funciona nuestro modelo. Es decir, una función que mide la diferencia entre las salidas que obtenemos de nuestro modelo y las salidas esperadas. Típicamente se suele utilizar como función de coste el error cuadrático medio (mean square error MSE), aunque se pueden utilizar otras.
![\[ \underline{\textbf{Mean Square Error}}: MSE = \frac{\sum_{i=1}^n (y - \hat{y})^{2} }{n} \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-8a6aaa3fa5e193140405fed3e2d3ebb7_l3.png "Rendered by QuickLaTeX.com")
Entonces ya podemos ver por qué Gradient Descent es tan útil. Al intentar minimizar dicha función, se minimizarán los errores entre la salida esperada y la salida dada por nuestro modelo, y éste será más preciso. El algoritmo nos encontrará los parámetros del modelo para que ésto suceda.
¿Cómo lo consigue?
Si dibujamos una función convexa, parece claro que podemos encontrar un mínimo fácilmente. Una de las propiedades de una función convexa es que, encontrado un mínimo, éste será el mínimo global de la función. es decir, no habrá otro valor más bajo para la función. Pero, ¿cómo se calcula ese mínimo matemáticamente? Derivando. La derivada de una función en un punto nos dará la pendiente de la recta tangente a dicho punto, siendo la pendiente el ángulo que forma la recta con la dirección positiva del eje de las abscisas. Si esa pendiente es igual a cero, significará que la recta es paralela al eje de abscisas y por lo tanto dicho punto será un mínimo.
Pero encontrarse una función de coste convexa no es lo normal. Lo habitual es encontrarnos una función de este tipo, una no convexa:
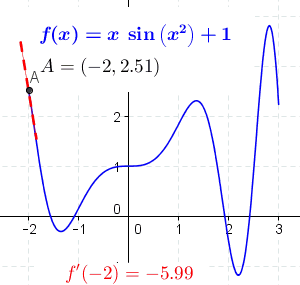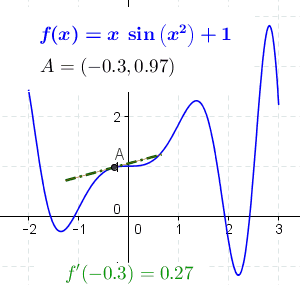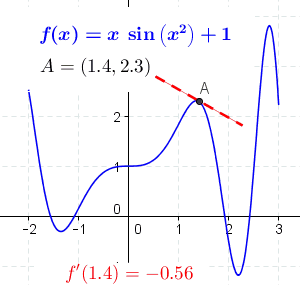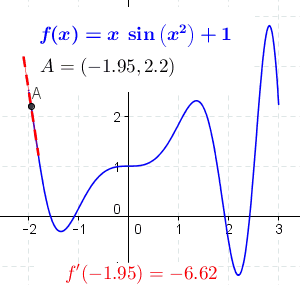
Fuente Wikipedia
Es fácil ver que en funciones con esta forma no existe un único valor mínimo. Podemos tener mínimos locales además del mínimo global. Además también podemos tener en la función puntos que también cumplen que la derivada de la función en ese punto es cero, como máximos locales, el máximo global o puntos de inflexión.
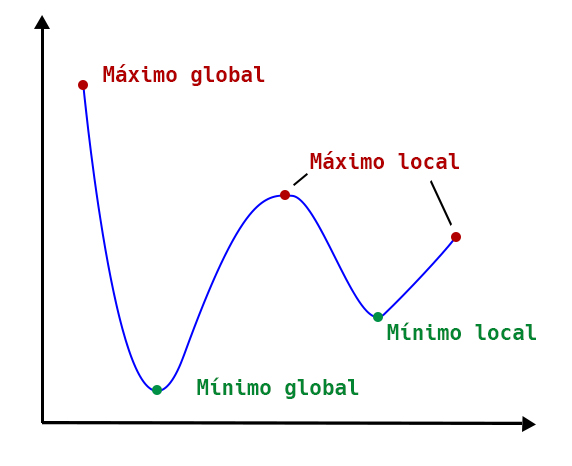
Al tener tantos posibles puntos que cumplen la condición de pendiente igual a cero tenemos un problema. ¿Cómo lo resolvemos? Vamos verlo con un ejemplo.
Resulta que formas parte una expedición científica a un nuevo planeta con una orografía que hace que recorrer la cordillera montañosa Kunlun sea cosa de niños. Serás teletransportado a un punto aleatorio del terreno. Allí tendrás que realizar varios experimentos. Una vez completada tu misión, deberás alcanzar un mínimo (local o global) del planeta. Éste será el punto de recogida. Un pequeño detalle: no hay luz de ningún Sol, el planeta es un mundo oscuro en el que la noche es eterna. La linterna que llevas en tu equipo sólo tiene batería para realizar los experimentos. Una vez acabados, irás a ciegas. ¿Cómo consigues llegar al punto de extracción?
Una vez terminada la tarea para la que fuiste teleportado tendrías que actuar de la siguiente manera.
- Primero, calcular, gracias al tricorder que contiene tu equipo básico, la mayor pendiente alrededor del punto en el que te encuentras. El tricorder realiza ese análisis calculando el gradiente. El gradiente es la generalización vectorial de la derivada. Es un vector que tiene las mismas dimensiones que nuestra función, e indica la dirección en la cual la función varía más rápidamente y su módulo representa el ritmo de variación de la función en la dirección de dicho vector gradiente.
![\[ \nabla (f)= (\frac{\partial f}{\partial x_{1}} + \frac{\partial f}{\partial x_{2}} + ... + \frac{\partial f}{\partial x_{n}}) \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-ef3570b5b75dcfd6eb62c7f7f61c7e5f_l3.png "Rendered by QuickLaTeX.com")
Esa variación es positiva, y a nosotros nos interesa descender, no ascender. Así que lo tomamos negativo.
![\[ -\nabla (f) \]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-5d0dbf96f71bb139e5378c19c300082c_l3.png "Rendered by QuickLaTeX.com")
- Segundo. Ya conoces la dirección en la cual el terreno cambia más rápidamente para descender. Ahora tendrás que avanzar en dicha dirección una distancia determinada.
- Tercero. Te paras, y vuelves a realizar los pasos primero y segundo, hasta que la pendiente sea cero o muy cercana a cero. En ese punto habremos encontrado un mínimo local de la función.
Gráficamente estaríamos haciendo lo siguiente:
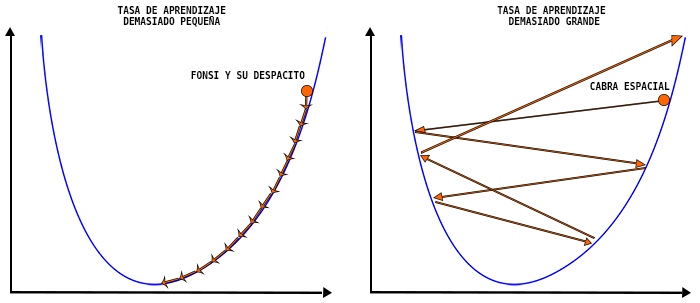
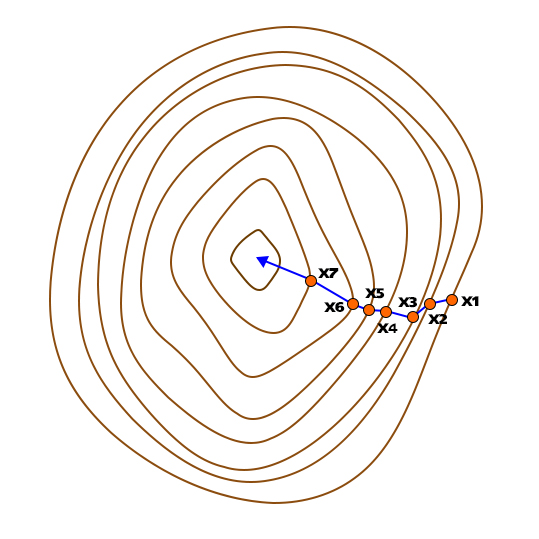 Pero ¡ojo!, que nos falta un detalle muy importante. En el segundo paso hemos dicho que avanzamos una distancia determinada, pero ¿cuánta? La gravedad en el planeta es menor que en La Tierra, ¿podemos saltar cuál cabra espacial? A la cantidad que debemos andar se la llama tasa de aprendizaje del algoritmo, η. La tasa de aprendizaje fija un peso al gradiente, con lo que decide cuánto afecta el gradiente a nuestra ruta. Esto es muy importante, ya que, si elegimos saltar como cabras, puede que nunca lleguemos a encontrar un mínimo pudiendo pasar por encima de éste en cada salto. Si por el contrario vamos deees…paaaa….cito, pasito a pasito….suave, suavecito…corremos el riesgo de tardar muchísimo en alcanzar el mínimo, y llegar tarde a la zona de extracción, quedando atrapados en el planeta.
Pero ¡ojo!, que nos falta un detalle muy importante. En el segundo paso hemos dicho que avanzamos una distancia determinada, pero ¿cuánta? La gravedad en el planeta es menor que en La Tierra, ¿podemos saltar cuál cabra espacial? A la cantidad que debemos andar se la llama tasa de aprendizaje del algoritmo, η. La tasa de aprendizaje fija un peso al gradiente, con lo que decide cuánto afecta el gradiente a nuestra ruta. Esto es muy importante, ya que, si elegimos saltar como cabras, puede que nunca lleguemos a encontrar un mínimo pudiendo pasar por encima de éste en cada salto. Si por el contrario vamos deees…paaaa….cito, pasito a pasito….suave, suavecito…corremos el riesgo de tardar muchísimo en alcanzar el mínimo, y llegar tarde a la zona de extracción, quedando atrapados en el planeta.
Con lo que el plan para llegar al punto de extracción es el siguiente:
- Primero, con el gradiente averiguamos hacia dónde tenemos que andar.
![\[ -\nabla (f)\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-44d2198698670faeff287b21cceb7248_l3.png "Rendered by QuickLaTeX.com")
- Segundo, se elige una distancia a recorrer, esto es, la tasa de aprendizaje η.
- Tercero, nos movemos según el gradiente, multiplicando éste por la distancia a recorrer elegida.
![\[ -\eta\cdot\nabla (f)\]](https://koldopina.com/wp-content/ql-cache/quicklatex.com-10b1ae53185bc08b8cb0f5ee97bbfb84_l3.png "Rendered by QuickLaTeX.com")
- Cuarto, nos paramos y repetimos los pasos anteriores.
Ésta es la lógica del algoritmo Gradient Descent.
Las tres versiones más utilizadas del algoritmo Gradient Descent son:
- Stochastic Gradient Descent.
- Batch Gradient Descent.
- Mini-Batch Gradient Descent.
Espero que os haya aclarado, aunque solo sea un poco. el funcionamiento de este algoritmo.




One Comment
Fernando Rios
11 febrero, 2020 at 06:18Tremendo, excelente