
Hoy vamos a raspar un poco alguna web para obtener información que nos sea útil, es decir, vamos a hacer un poco de Web Scraping.
¿Qué significa eso de Web Scraping?. Básicamente consiste en analizar el código HTML de una página web y extraer la información que te resulte interesante.
Por lo tanto, es imprescindible conocer los elementos y estructura de un documento HTML. Los elementos HTML están contenidos entre dos etiquetas. La primera etiqueta indica dónde empieza el elemento y la segunda etiqueta indica dónde termina. Entre ellas se encuentran los contenidos. De éstos contenidos es de dónde extraeremos información.
Un ejemplo de elemento HTML podría ser este:
<p> Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. </p>
donde el contenido se encuentra entre dos etiquetas: <p> indica el comienzo del elemento, en este caso un parrafo, y </p> indica dónde termina dicho elemento.
Los elementos más comunes en un documento HTML pueden ser:
- Los encabezados, definidos por etiquetas <h1>, <h2>, <h3>…<h6>. En este orden, el tamaño de la fuente va decreciendo.
- Las secciones, definidos por la etiqueta <div>.
- Los párrafos, definidos por la etiqueta <p>.
- Los hipervínculos, definidos por la etiqueta <a>.
- Las listas definidas por la etiqueta <ol> las numeradas y la etiqueta <ul> las no numeradas.
- Las tablas, definida por la etiqueta <table>.
Además, un elemento HTML pueden ir definido por un identificador y/o una clase, lo cual, como veremos más adelante, nos facilitará sobremanera el trabajo.
<p id = "top secret" class="important">Aquí comienza un párrafo de muchísima importancia</p>
En este link podéis encontrar más información sobre código HTML.
Ahora que tenemos algunas nociones básicas de elementos HTML, vamos a meternos en harina.
Se me ha ocurrido obtener las direcciones de todas las tiendas que LEGO tiene en el mundo. Para ello vamos a utilizar Python y BeautifulSoup, una fantástica librería que nos ayudará a extraer los datos que necesitamos. También utilizaremos la librería request, para obtener todo el código HTML de la página, haciendo una petición HTTP.
Pero antes de escribir ni una sola línea de código, lo primero que debemos hacer es inspeccionar la página en cuestión, ésta.
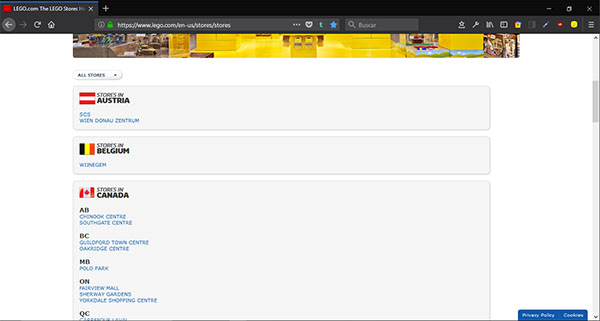
Imagen 1
Lo haremos con la herramienta inspector que se encuentra en el kit para desarrollador web que incluyen muchos navegadores. Yo estoy usando Firefox como navegador. Para abrir la herramienta inspector basta con pulsar Crtl+Mayús.+C. Al hacerlo, nos aparece algo así:
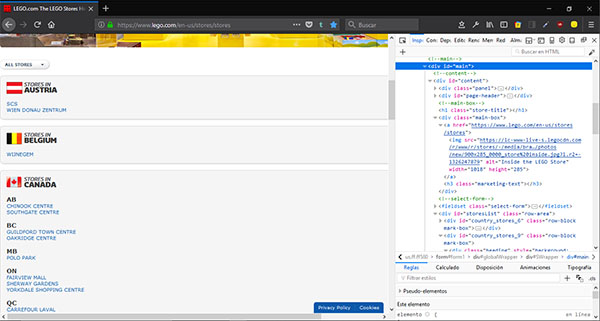
Imagen 2
A la izquierda podemos ver a simple vista que para cada país hay un bloque en el que aparecen los links a sus tiendas. El código HTML se repite para cada bloque, y tiene esta pinta. Nos fijaremos en las líneas que he marcado en verde.

Imagen 3
De la tercera línea obtendremos el nombre del país, que se encuentra contenido en un elemento header con etiquetas h3. Y de la última, obtendremos la url de la página de detalle de la tienda, que se encuentra contenida en un elemento con etiquetas a.
El cómo lo vamos a hacer lo veremos más adelante.
Ahora vamos a inspeccionar el código HTML de la página de detalle, por ejemplo del primer link, la tienda SCS en Austria. La sección del código que nos va a interesar va a ser esta:
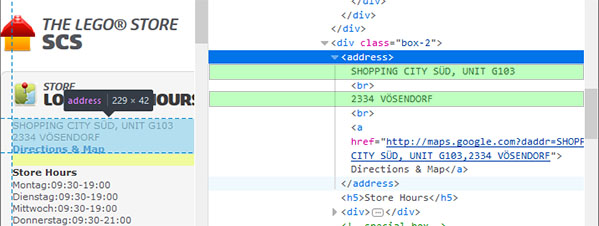
Imagen 4
De ella obtendremos el texto que se encuentra contenido en la etiqueta address, marcado en verde, que corresponde a la dirección de la tienda.
Bien, una vez que hemos hecho el trabajo de detective y sabemos qué queremos obtener y dónde se encuentra, nos ponemos manos a la obra.
Python
Empezamos importando las librerías que vamos a utilizar. Creamos una variable lista donde iremos colocando los datos de las tiendas, y realizamos una petición HTTP para obtener el documento HTML.
import pandas as pd import requests from bs4 import BeautifulSoup from datetime import datetime lego_stores_list = [] lego_stores_url = 'https://www.lego.com/en-us/stores/stores' lego_stores_req = requests.get(lego_stores_url)
Ahora ya tenemos creado un objeto Response, lego_stores_req, del que podemos obtener un montón de información, como por ejemplo el código que indica el status de la página, o el documento HTML (tipo string) de la página. A nosotros nos va a interesar éste último. Con ese string vamos a crear un objeto Beautiful Soup:
lego_stores_html = lego_stores_req.text lego_stores_soup = BeautifulSoup(lego_stores_html, "html.parser") print (type(lego_stores_soup))
<class 'bs4.BeautifulSoup'>
Al objeto BeautifulSoup le hemos pasado dos parámetros. El primero es el string del código HTML y el segundo es el parser que queremos usar. Puedes usar el parser que mejor se ajuste a tus necesidades.
Perfecto, ahora ya estamos preparados para extraer los datos interesantes. Para ello BeautifulSoup nos ayuda con el método find_all. En la documentación puedes ver la cantidad de formas de utilizarlo. Nosotros vamos a pedirle que nos extraiga todos los bloques que se encuentres bajo la etiqueta div con clase row-block mark-box, con lo que obtendríamos un objeto ResultSet con todos los bloques de código html como el que aparece en la Imagen 3.
Este objeto ResultSet lo recorreremos para extraer dos cosas, fijándonos en la Imagen 3:
- El texto del país: con la ayuda del método find, extraeremos el código contenido en la etiqueta h3. Se crea un objeto Tag, el cual incluye el método get_text que devuelve el texto dentro de la etiqueta.
- El link a la página de detalle de la tienda: volveremos a utilizar find_all para extraer el bloque que corresponde a la etiqueta a de clase btn-details, que es donde se encuentra la url de la página de detalle de la tienda. Esto crea un otro objeto ResultSet que contiene todos los bloques de código contenidos en las diferentes etiquetas con las caracteristicas anteriores. Recorremos dichos bloques de este ResultSet, que son tipo Tag, y extraemos de ellos el link con el método .get() pasándole de argumento ‘href’.
Vamos a ver cómo sería el código en Python
div = lego_stores_soup.find_all('div', {"class": "row-block mark-box"})
for div_block in div:
h3 = div_block.find('h3')
lego_store_country = h3.get_text().strip()
print (lego_store_country)
lego_stores_links = div_block.find_all("a", {"class": "btn-details"}, href=True)
for link in lego_stores_links:
print(link.get('href'))
Austria https://www.lego.com/en-us/stores/stores/at/vienna-scs https://www.lego.com/en-us/stores/stores/at/vienna-dz Belgium https://www.lego.com/en-us/stores/stores/be/wijnegem Canada https://www.lego.com/en-us/stores/stores/ca/chinook-ctr https://www.lego.com/en-us/stores/stores/ca/southgate https://www.lego.com/en-us/stores/stores/ca/guildford ...
Ahora, en cada iteración vamos a obtener la dirección de la tienda de su página de detalle, haciendo lo siguiente:
1.- Petición HTTP para obtener otro objeto Response, store_req, del que utilizaremos el texto para crear un objeto BeautifulSoup, store_soup.
store_url = link.get('href')
store_req = requests.get(store_url)
store_soup = BeautifulSoup(store_req.text, "html.parser")
2.- Recordando la Imagen 4, utilizaremos la función find para extraer el texto contenido en la etiqueta address, creando un objeto Tag, store_address, del que extraeremos el contenido con el método contents. Utilizamos éste método y no get_text porque bajo la etiqueta address existen otras etiquetas. El método contents devuelve una lista donde los elementos son todos los textos entre etiquetas, incluidas las etiquetas. Tenemos que ver qué elementos de dicha lista nos interesan.
store_address = store_soup.find("address")
print(store_address.contents)
['\r\n\t\t\t\t\t WAGRAMER STRAßE 81, #928B', <br/>, '1220 VIENNA', <br/>, '\n', <a href="http://maps.google.com?daddr=WAGRAMER STRAßE 81, #928B,1220 VIENNA">Directions & Map</a>, '\n']
Para obtener la dirección, concatenamos los elementos 0 y 2 de la lista, y, con la función strip(), eliminamos los espacios en blanco al principio y al final, los retornos de carro (\r), los saltos de línea (\n) y tabulaciones (\t).
link_address = store_address.contents[0].strip() + ' ' + store_address.contents[2].strip()
¡Ojito!. Mucha atención a la dirección en caracteres chinos. Hay que pasarla a otro formato, itf-8 por ejemplo.
if lego_store_country == 'China':
link_address = link_address.encode('utf8')
3.- Añadimos el país, la url y la dirección a nuestra lista de listas
lego_stores_list.append([lego_store_country, store_url, link_address])
Podemos pasar el resultado a un dataframe y a un archivo csv.
lego_stores_df = pd.DataFrame(lego_stores_list, columns = ['country','store_url', 'address']) now = datetime.now() filename = 'Py_Lego_stores_%d%d%d.csv' %(now.year, now.month, now.day) lego_stores_df.to_csv(filename, sep = ';', index = False, encoding = 'utf-8')
Y para finalizar, hacemos un head al dataframe para comprobar los datos que hemos obtenido.
country store_url \
0 Austria https://www.lego.com/en-us/stores/stores/at/vi...
1 Austria https://www.lego.com/en-us/stores/stores/at/vi...
2 Belgium https://www.lego.com/en-us/stores/stores/be/wi...
3 Canada https://www.lego.com/en-us/stores/stores/ca/ch...
4 Canada https://www.lego.com/en-us/stores/stores/ca/so...
address
0 SHOPPING CITY SÜD, UNIT G103 2334 VÖSENDORF
1 WAGRAMER STRAßE 81, #928B 1220 VIENNA
2 SPACE 526, TURNHOUTSEBAAN 5 2110 WIJNEGEM
3 6455 MACLEOD TRAIL SW, SP 203 CALGARY AB T2H 0K8
4 5015-111 ST NW SPACE #424 EDMONTON AB T6H 4M6
¡Os invito a probar Beautiful Soup!.
Puedes descargarte el código de mi ![]()




