Entre las mejoras que se introdujeron en la versión 4 de Neo4j, una de las más destacadas fue Fabric.
Vamos a ver qué es esto de Fabric y qué aporta al ecosistema de Neo4j, con un ejemplo práctico, que siempre rasca menos al tragar. Pero antes, una breve introducción.
Fabric te permite almacenar y recuperar información de varias bases de datos Neo4j. Estas bases de datos pueden estar en el mismo DBMS (Database Management System), o en varios DBMSs, ya sea en instancias locales, o en instancias remotas. Y todo utilizando una única consulta de Cypher.
Así pues, Fabric nos aporta:
- Una vista unificada de datos locales y distribuidos, accesible a través de una única conexión de cliente y sesión de usuario.
- Mayor escalabilidad para operaciones de lectura/escritura, volúmenes de datos y simultaneidad.
- Tiempo de respuesta predecible para las consultas ejecutadas durante una operación normal, una conmutación u otros cambios en la infraestructura.
- Alta disponibilidad y No Single Point of Failure para grandes volúmenes de datos.
En términos prácticos, Fabric nos proporciona la infraestructura y las herramientas para:
- Data Federation: Capacidad de acceder a datos disponibles en fuentes distribuidas en forma de grafos inconexos.
- Data Sharding: Capacidad de acceder a los datos disponibles en fuentes distribuidas en forma de un gráfico común particionado en múltiples bases de datos.
Resumiendo, con Fabric, una consulta Cypher puede almacenar y recuperar datos de varios grafos federados y fragmentados.
Perfecto. Vamos a probar esta funcionalidad de Ne4j con un ejemplo muy practico, rápido y sencillo de implementar.
Yo voy a utilizar dos equipos distintos, un sobremesa y un portátil, conectados a la misma red. Ambos con Windows 10 como SO. En cada uno de ellos tendré un Neo4j Desktop, con una instancia versión 4.3.2 (la última release en el momento de escribir este post) corriendo en cada uno de ellos.
Los datos, serán los identificadores de algunos pilotos de la Republica Galáctica, pertenecientes a dos sectores: Outer Rim Sector y Mid Rim Sector. En este caso sólo realizaremos Data Sharding, ya que los datos son dos particiones de información de los pilotos, y los dos grafos comparten el mismo modelo.
Paso I
En este primer paso, crearemos las bases de datos donde guardar la información.
Lo primero de todo será crear dentro de cada uno de los Neo4j Desktops, la correspondiente instancia. Una vez hecho, tendría esta pinta:
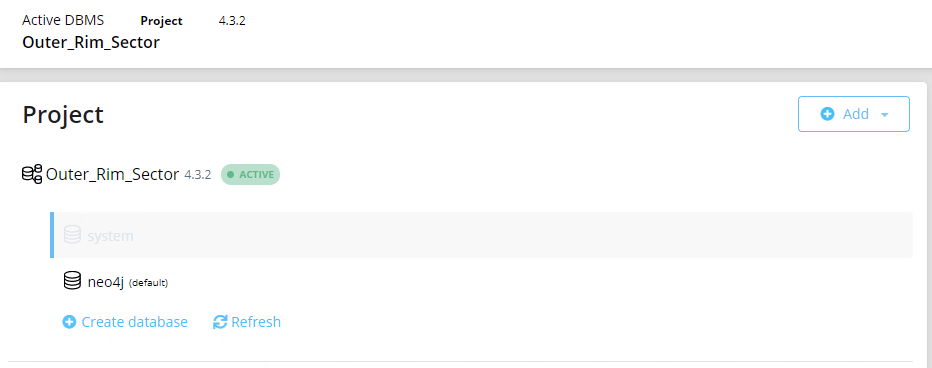

El siguiente paso, es crear una base de datos en cada una de las instancias de Neo4j, la del sobremesa y la del portátil.
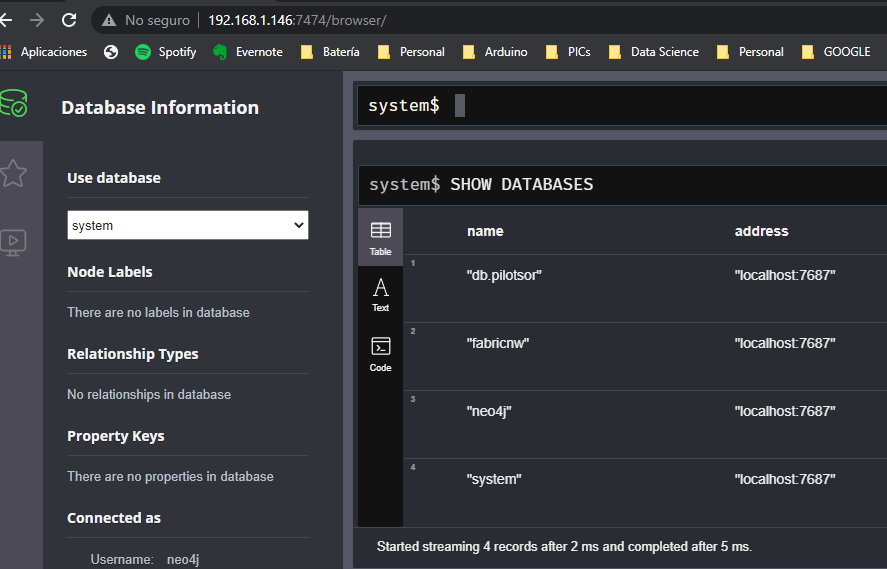
Comprobamos las bases de datos existentes. Al ser una instancia nueva, deberíamos tener dos: system y neo4j.

Creamos nuestra base de datos de pilotos
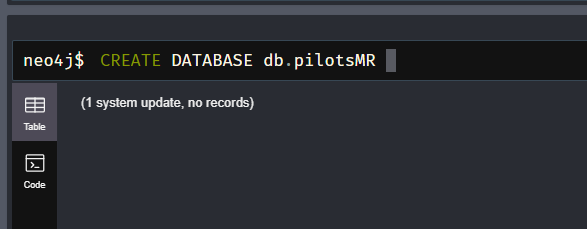
Comprobamos que se ha creado correctamente:

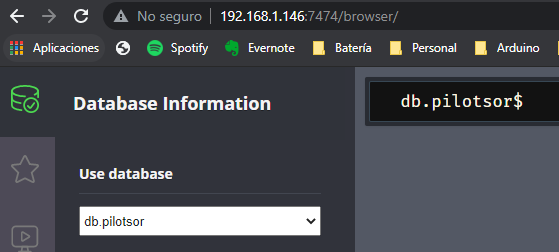
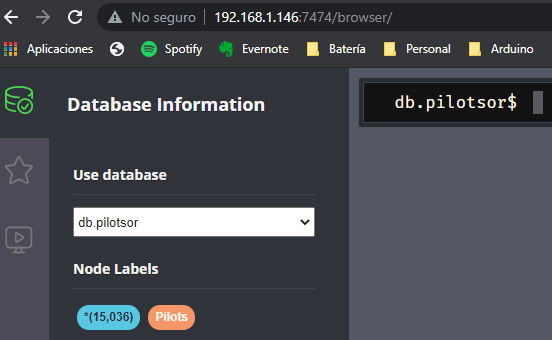
Haremos lo mismo en la otra instancia, creando la base de datos db.pilotsor.
Paso II – Configurar las conexiones y Fabric
Para que las dos instancias de Neo4j (sobremesa y portátil), puedan comunicarse entre ellas, hay que hacer un par de cosas:
- Primera: al estar utilizando Windows como SO, tenemos que activar la detección de redes y el uso compartido de archivos.
- En las configuraciones respectivas de nuestras bases de datos, en el fichero neo.conf, tenemos que descomentar esta línea y añadir la ip correspondiente a la máquina:
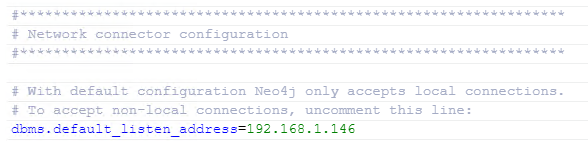
Con esto, ya deberíamos poder abrir un navegador y conectar con la url correspondiente del browser de neo4j de la máquina remota.
Lo siguiente sería añadir a este archivo neo.conf, el setup de fabric, que sería el siguiente:
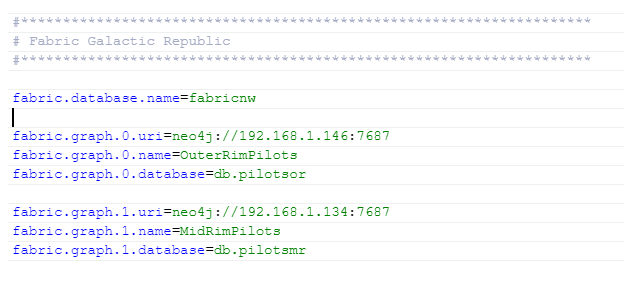
La línea fabric.database.name se utiliza para decirle a Neo el nombre que queremos darle a la base de datos virtual de Fabric. Espera, espera…¿base de datos virtual de Fabric?
Si. Fabric, para poder acceder a la información de las diferentes bases de datos, necesita un punto de entrada. Así que crea una base de datos virtual en la instancia de neo4 que se utilizará para lanzar las queries contra las diferentes fuentes. Esta base de datos virtual no almacena ningún dato, únicamente transmite la información que están almacenados en otros repositorios.
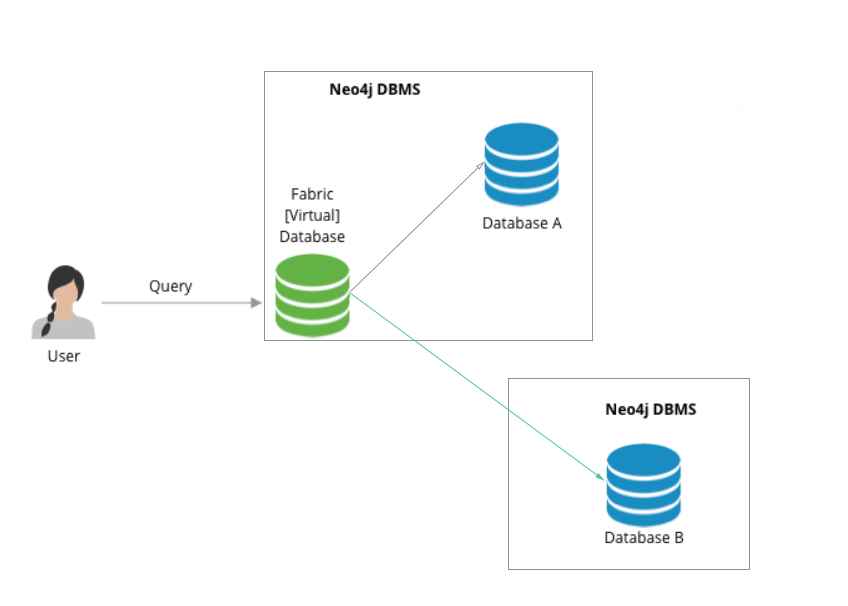
Este sería un esquema de la arquitectura que hemos montado:
El resto de líneas corresponden a:
- fabric.graph.0.uri: la dirección url de cada instancia
- fabric.graph.0.name: un nombre, el que nosotros queramos, con el que identificar a cada base de datos. Este nombre lo utilizaremos más adelante para realizar consultas.
- fabric.graph.0.database: el nombre que le hemos dado a la base de datos al crearla (en minúsculas, ya que al crearla, aunque pongamos mayúsculas, neo4j pasa todo a minúsculas).
Paso III – Ingesta de datos
Como quería hacer un ejercicio sencillo, para crear los datos de los pilotos de La República vamos a lanzar estas queries, una para cada base de datos:
Base de datos db.pilotsor
CREATE CONSTRAINT ON (Pilots:Pilots) ASSERT Pilots.id IS UNIQUE ;
WITH range(0,15035) as rango
UNWIND rango as r
CREATE(n:Pilots{id:"OR_"+r});Base de datos db.pilotsmr
CREATE CONSTRAINT ON (Pilots:Pilots) ASSERT Pilots.id IS UNIQUE ;
WITH range(0,10000) as rango
UNWIND rango as r
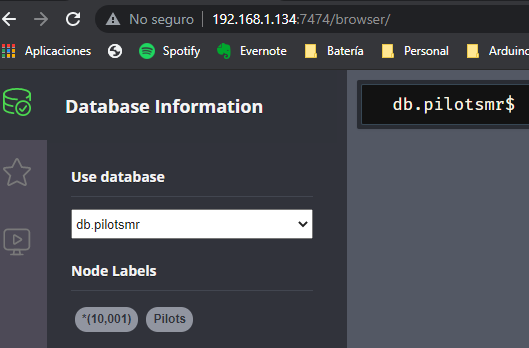
CREATE(n:Pilots{id:"MR_"+r})De esta manera creamos 10001 pilotos en db.pilotsmr y 15036 pilotos en db.pilotsor
Paso IV – Obtener información
Ya tenemos todo el entorno construido para realizar alguna consulta.
Vamos a comprobar qué bases de datos tenemos en la instancia 192.168.1.146, que es la instancia en la que configuramos Fabric. Deberían aparecer la base de datos virtual de Fabric, la base de datos db.pilotsor, y las dos bases de datos que se crean por defecto, neo4j y system:
Y en la instancia 192.168.1.134, las mismas bases de datos creadas por defecto, y la db.pilotsmr

Vamos a lanzar algunas consultas.
Con la primera realizaremos un conteo de los nodos tipo Pilots que existen en ambos grafos. Utilizaremos el browser de Neo4j conectado a la base de datos virtual de Fabric, que en el setup hemos llamado fabricnw:

Esta misma consulta se puede realizar utilizando la sintaxis de Fabric:

Ahora podemos pedirle, en la misma query, información de una y otra base de datos:
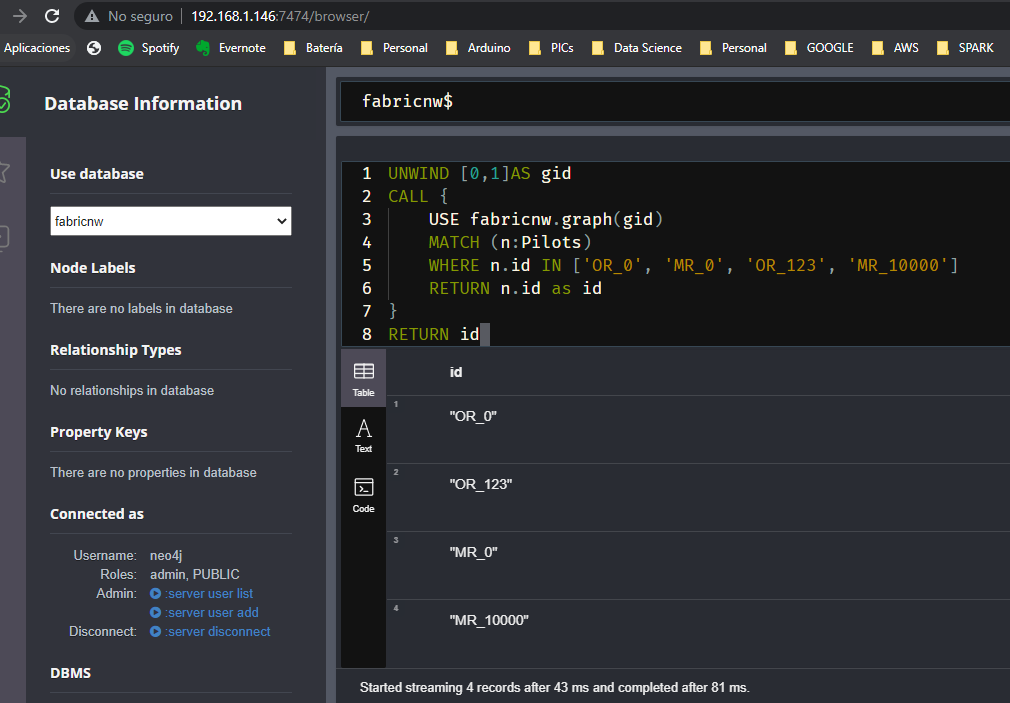
Como veis, Fabric funciona perfectamente, aportando una herramienta que abre un montón de nuevas posibilidades para tus proyectos con Neo4j.
Si queréis aprender más, aquí tenéis toda la documentación de Fabric.